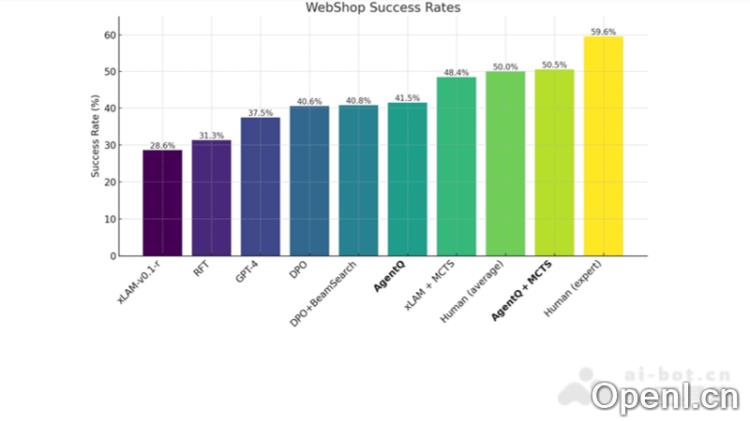
Agent Q是一种创新的自监督代理推理和搜索框架,由MultiOn公司与斯坦福大学共同开发。此产品结合了引导式蒙特卡洛树搜索(MCTS)、AI自我批评及直接偏好优化(DPO)等先进技术,使得AI模型能够通过迭代微调和基于人类反馈的强化学习实现自我完善。Agent Q在网页导航和多步任务执行方面表现卓越,尤其在OpenTable的真实预订任务中,成功率从18.6%跃升至95.4%,展现了AI在自主性和复杂决策能力上的重大进步。
Agent Q 是什么
Agent Q是由MultiOn公司和斯坦福大学联合推出的前沿自监督代理推理与搜索框架。此框架利用引导式蒙特卡洛树搜索(MCTS)、AI自我批评及直接偏好优化(DPO)等技术,赋予AI模型通过迭代微调和人类反馈强化学习来进行自我提升的能力。在网页导航和多步任务执行方面,Agent Q展现了卓越的性能,特别是在OpenTable的真实预订任务中,成功率从18.6%提升至95.4%,标志着AI在自主性和复杂决策能力上的显著突破。
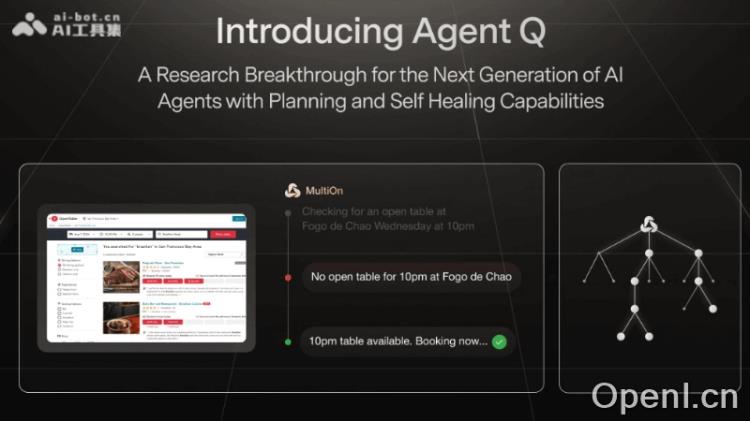
Agent Q 的主要功能
- 引导式搜索:采用蒙特卡洛树搜索(MCTS)算法来优化在复杂环境中的探索与决策。
- 自我批评:具备自我评估能力,在每个步骤中提供反馈,以细化决策过程。
- 迭代微调:通过直接偏好优化(DPO)算法,从成功和失败的轨迹中学习,不断优化策略。
- 多步推理任务:能够处理需要多步推理和决策的复杂任务,如在线预订和电子商务平台操作。
- 零样本学习:即使在未接受特定任务训练的情况下,Agent Q也能展现出卓越的零样本性能。
Agent Q 的技术原理
- 引导式蒙特卡洛树搜索(MCTS):Agent Q应用MCTS算法来指导代理在网页环境中的探索。通过模拟潜在的行动路径,算法能够评估并选择最佳行动,从而在探索新信息与利用已知信息之间取得平衡。
- AI自我批评:在每个节点上,Agent Q生成可能的行动,并利用大型语言模型(LLM)对这些行动进行自我评估,提供中间反馈以指导搜索步骤。
- 直接偏好优化(DPO):这是一种离线强化学习方法,用于优化策略,使Agent Q能够从成功与失败的轨迹中学习。DPO算法通过直接优化偏好对来微调模型,而不依赖于传统的奖励信号。
- 策略迭代优化:通过结合MCTS生成的数据与AI自我批评反馈,Agent Q进行迭代微调以构建偏好对,从而优化模型性能。
Agent Q 的项目地址
- 产品网址:multion.ai(申请内测体验)
- 技术论文:https://multion-research.s3.us-east-2.amazonaws.com/AgentQ.pdf
Agent Q 的应用场景
- 电子商务:在模拟WebShop环境中,Agent Q能够自动化浏览和购买流程,帮助用户快速找到所需商品并完成交易。
- 在线预订服务:Agent Q可以在OpenTable等在线预订平台上为用户进行餐厅或酒店的预订,并处理所有相关步骤。
- 软件开发:该系统能够辅助软件开发,包括代码生成、测试以及文档编写,提高开发效率并减少人为错误。
- 客户服务:作为智能客服代理,Agent Q能够处理客户咨询,提供即时反馈并解决常见问题。
- 数据分析:Agent Q具备分析大量数据的能力,能够为企业提供洞察与建议,帮助做出更为数据驱动的决策。
- 个性化推荐:根据用户的历史行为和偏好,Agent Q能够提供个性化的内容或产品推荐。
常见问题
- Agent Q能应用于哪些领域?Agent Q广泛适用于电子商务、在线预订、软件开发、客户服务、数据分析及个性化推荐等多个领域。
- 如何申请内测体验?用户可以通过访问产品官网申请内测体验,具体流程会在网站上提供。
- Agent Q的技术基础是什么?Agent Q结合了引导式蒙特卡洛树搜索、AI自我批评和直接偏好优化等多项技术,以实现高效的决策与推理。
- Agent Q的零样本学习能力如何?Agent Q即使在未进行特定任务训练的情况下,也能展现出高成功率,具备良好的零样本学习能力。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...

 粤公网安备 44011502001135号
粤公网安备 44011502001135号