Jamba是AI21 Labs推出的首款基于Mamba架构的高性能大语言模型,结合了Mamba结构化状态空间模型(SSM)与传统Transformer结构,具备高质量输出、高吞吐量和低内存占用等显著优点。该模型提供256K的上下文窗口,使其在处理长文本时更为高效,同时以开放权重形式发布,遵循Apache 2.0开源许可,鼓励社区进行研究和优化。
Jamba是什么
Jamba是AI21 Labs研发的首个基于Mamba架构的生产级大语言模型。与大多数依赖Transformer结构的模型(如GPT、Gemini和Llama)不同,Jamba将Mamba结构化状态空间模型(SSM)与传统Transformer架构相结合,旨在提升模型的性能与效率。其256K的上下文窗口配置显著提高了长文本处理的吞吐量与效率。
目前,Jamba以开放权重形式发布,遵循Apache 2.0开源许可,鼓励广大研究者和开发者进行探索与改进。AI21 Labs预计将在未来几周推出经过微调并具备更好安全性的版本。

Jamba的官网入口
- 官方项目主页:https://www.ai21.com/jamba
- 官方博客介绍:https://www.ai21.com/blog/announcing-jamba
- Hugging Face地址:https://huggingface.co/ai21labs/Jamba-v0.1
Jamba的主要特性
- SSM-Transformer混合架构:Jamba是第一款将Mamba SSM(结构化状态空间模型)与Transformer架构相结合的生产级模型,该创新混合架构旨在提升模型性能与效率。
- 大容量上下文窗口:Jamba具备256K的上下文窗口,使其能够处理更长的文本序列,适用于复杂的自然语言处理任务。
- 高吞吐量:与同类Mixtral 8x7B模型相比,Jamba在处理长上下文时实现了3倍的吞吐量提升,能更高效处理大量数据。
- 单GPU大容量处理:Jamba能够在单个GPU上处理高达140K的上下文,显著提高了模型的可访问性与部署灵活性。
- 开放权重许可:Jamba的权重以Apache 2.0许可发布,为研究者和开发者提供了自由使用、修改和优化模型的权限,促进技术共享与创新。
- NVIDIA API集成:Jamba将作为NVIDIA NIM推理微服务在NVIDIA API目录中提供,帮助企业开发者轻松部署Jamba模型。
- 优化的MoE层:Jamba在混合结构中采用MoE(混合专家)层,仅在推理时激活部分参数,提高了模型的运行效率与性能。
Jamba的技术架构
Jamba的架构采用块和层次的方法,使其能够成功整合Mamba SSM与Transformer两种架构。每个Jamba块包含一个注意力层或Mamba层,后接多层感知器(MLP),从而在八层中形成一个Transformer层的比例。
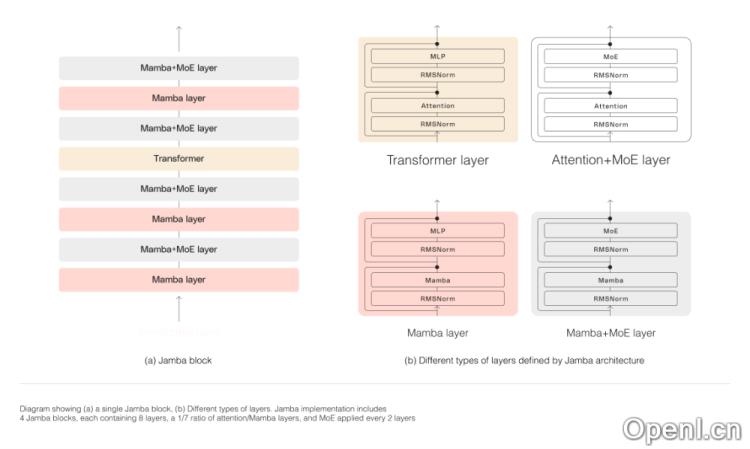
此外,Jamba利用MoE增加模型总参数量,同时在推理中简化活跃参数的使用,从而在计算需求不增加的情况下提升模型容量。AI21 Labs优化了MoE层及专家数量,以最大限度提升单个80GB GPU上的模型质量与吞吐量。
Jamba的性能对比
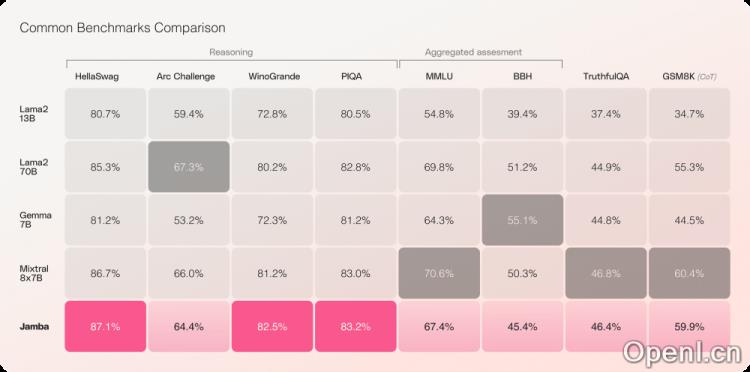
根据AI21 Labs的报告,Jamba模型在多项基准测试(如HellaSwag、ArcChallenge、MLLU等)中表现出色,在语言理解、科学推理和常识推理等多种任务上,Jamba与同类模型(如Llama2 13B、Llama2 70B、Gemma 7B、Mixtral 8×7B)相比,表现不相上下,甚至超越部分模型。

 粤公网安备 44011502001135号
粤公网安备 44011502001135号