AnimateDiff是什么?
AnimateDiff是一款由上海人工智能实验室、香港中文大学和斯坦福大学的研究团队共同开发的创新框架,旨在将个性化的文本到图像模型扩展为动画生成工具。其核心优势在于,AnimateDiff能够充分利用从庞大视频数据集中学习到的运动先验知识,作为Stable Diffusion文本生成图像模型的插件,帮助用户将静态图像转化为生动的动态动画。该框架的设计目的是简化动画创作过程,使用户能够仅通过文本描述来控制动画的内容和风格,而无需进行复杂的模型调整。
AnimateDiff的官网入口
- 官方项目主页:https://animatediff.github.io/
- Arxiv研究论文:https://arxiv.org/abs/2307.04725
- GitHub代码库:https://github.com/guoyww/animatediff/
- Hugging Face Demo:https://huggingface.co/spaces/guoyww/AnimateDiff
- OpenXLab Demo:https://openxlab.org.cn/apps/detail/Masbfca/AnimateDiff
AnimateDiff的主要功能
- 个性化动画创作:AnimateDiff使用户能够将个性化的文本到图像模型(如Stable Diffusion)转变为动画生成工具。用户只需输入文本描述,模型就可以生成符合描述的动画序列,而不仅限于静态图像。
- 无需额外模型调整:AnimateDiff的一大亮点是,它不需要对个性化模型进行额外的调整。用户可以直接利用框架内置的运动建模模块,将其与个性化T2I模型结合,实现动画生成。
- 保持风格一致性:在动画生成过程中,AnimateDiff能够保持个性化模型的领域特性,确保生成的动画内容与用户所定制的风格和主题相符。
- 跨领域支持:AnimateDiff兼容多种领域的个性化模型,包括动漫、2D卡通、3D动画及现实摄影等,用户可以在不同风格和主题间灵活切换,创作多样化的动画作品。
- 简易集成:AnimateDiff的设计理念使其易于与现有个性化T2I模型结合,用户无需具备深厚的技术背景即可轻松使用,极大地降低了使用门槛。
AnimateDiff的工作原理
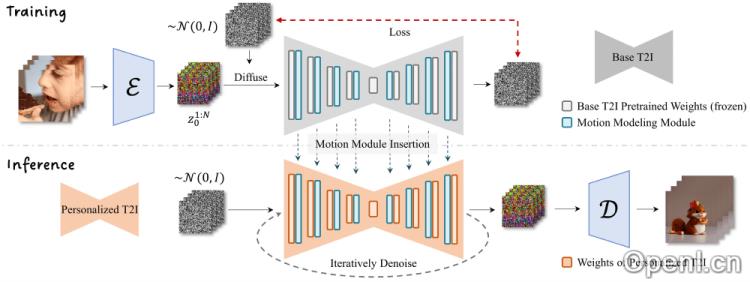
- 插入运动建模模块:首先,AnimateDiff会在现有的文本到图像模型中插入一个专门设计的运动建模模块,该模块负责理解并生成动画中的运动信息,并能在模型的不同分辨率层面上工作,确保生成动画的细节一致性。
- 视频数据训练:运动建模模块通过在大规模视频数据集上进行训练,学习视频中的运动模式。该训练过程是在模型的冻结状态下进行的,以保持基础T2I模型的图像生成能力不受影响。
- 时间维度的注意力机制:AnimateDiff采用标准的注意力机制(如Transformer中的自注意力)来处理时间维度,使模型在生成每一帧动画时,能够参考前后帧的信息,从而实现流畅的过渡和连贯的动作。
- 动画生成:待运动建模模块训练完成后,它可以插入到任何基于同一基础文生图模型的个性化模型中。用户输入文本描述时,模型结合文本内容和运动建模模块学习到的运动先验知识,生成与描述相符的动画序列。
应用场景
AnimateDiff适用于各种创作场景,包括数字艺术创作、游戏动画设计、教育视频制作以及社交媒体内容生成等。无论是专业人士还是爱好者,都能利用这一工具实现个性化的动画表达,满足不同领域的需求。
常见问题
1. AnimateDiff是否需要编程知识?
不需要。AnimateDiff的设计使得用户即使没有技术背景,也能轻松使用。
2. 我可以使用AnimateDiff生成任何风格的动画吗?
是的,AnimateDiff支持多种风格的个性化模型,包括动漫、2D卡通和3D动画等。
3. AnimateDiff是否免费使用?
AnimateDiff的基本功能是免费的,但某些高级功能可能需要付费。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...

 粤公网安备 44011502001135号
粤公网安备 44011502001135号