AnyText是阿里巴巴智能计算研究院推出的一款创新型多语言视觉文本生成与编辑模型,旨在实现图像中文本的准确与连贯渲染。该模型采用扩散技术,融合了辅助潜在模块与文本嵌入模块,能够有效解决生成图像中文本模糊、不可读或错误的难题,从而提升文本书写的准确度。
AnyText是什么
AnyText是由阿里巴巴智能计算研究院开发的基于扩散的多语言视觉文本生成与编辑模型,专注于在图像中实现文本的精准与连贯呈现。其核心架构包括两个主要模块:辅助潜在模块和文本嵌入模块。辅助潜在模块通过文本字形、位置和蒙版图像等输入信息生成文本的潜在特征,而文本嵌入模块则采用OCR技术对笔画数据进行编码,结合图像标题嵌入,实现文本与背景的无缝融合。这项技术有效克服了生成文本区域时的模糊、不可读和错误等挑战,显著提高了图像中文本的书写精度。

GitHub项目:https://github.com/tyxsspa/AnyText
论文地址:https://arxiv.org/abs/2311.03054
ModelScope:https://modelscope.cn/studios/damo/studio_anytext
Hugging Face:https://huggingface.co/spaces/modelscope/AnyText
AnyText的主要功能
- 多语言生成:支持中文、英文、日文、韩文等多种语言的文本生成。
- 多行文本渲染:允许用户在图像的多个位置生成文本内容。
- 变形区域文本书写:能够在水平、垂直或曲线、不规则区域内生成文本。
- 文本编辑功能:支持在指定位置修改文本内容,同时保持与周围文本风格的一致性。
- 即插即用:可无缝集成至现有扩散模型中,提供文本生成能力。
AnyText的工作原理
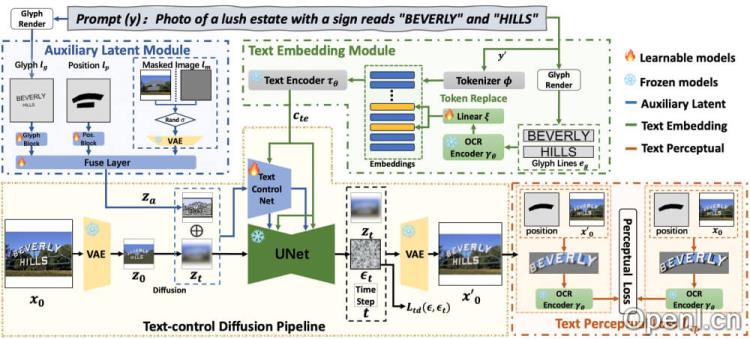
AnyText通过多个模块的协同作用,能够在图像中精准地生成和编辑多语言文本,并与背景无缝融合,具体如下:
- 文本控制扩散管线:
- 使用变分自编码器(VAE)对输入图像进行编码,生成潜在表示。
- 然后,通过扩散算法逐步向该潜在表示添加噪声,形成一系列时间步骤的噪声潜在图像。
- 在每个时间步骤,AnyText应用网络(TextControlNet)预测应添加到噪声潜在图像上的噪声,以控制文本生成。
- 辅助潜在模块:
- 该模块接收文本字形、位置和蒙版图像作为输入,生成辅助潜在特征图。
- 字形信息通过渲染文本到图像上生成,位置信息标记文本在图像中的位置,而掩膜图像指示在扩散过程中应保留的区域。
- 文本嵌入模块:
- 使用预训练OCR模型(如PP-OCRv3)提取文本笔画信息并进行编码。
- 这些编码与来自分词器的图像标题嵌入结合,生成融合的中间表示,随后通过交叉注意力机制映射到UNet的中间层。
- 文本感知损失:
- 在训练过程中,AnyText使用文本感知损失提高文本生成的准确性。
- 此损失通过比较生成图像和原始图像中的文本区域实现,专注于文本本身的正确性,排除背景、字符位置偏差、颜色或字体样式等因素。
- 训练与优化:
- AnyText的训练目标是最小化文本控制扩散损失和文本感知损失的加权和。
- 在训练过程中,模型通过调整权重比(λ)来平衡这两种损失。
如何使用AnyText生成文本
- 访问AnyText的ModelScope空间或Hugging Face演示
- 输入提示词,并选择文本的具体位置
- 最后点击运行,等待图像和文本的生成
应用场景
AnyText可广泛应用于广告创作、社交媒体内容生成、电子商务产品展示、图形设计等多个领域,帮助用户轻松生成符合需求的图像文本。
常见问题
1. AnyText支持哪些语言?
AnyText支持多种语言,包括中文、英文、日文、韩文等。
2. 如何保证生成文本的准确性?
AnyText通过文本感知损失和多模块协作来提高生成文本的准确性,确保文本与背景的无缝融合。
3. 使用AnyText需要什么技术背景吗?
用户不需要深厚的技术背景,只需按照简单的步骤输入提示词和选择位置即可轻松生成文本。

 粤公网安备 44011502001135号
粤公网安备 44011502001135号