CogAgent是一款由清华大学与智谱AI合作开发的先进多模态视觉大模型,专注于图形用户界面(GUI)的理解与导航。它通过视觉模态感知GUI界面,摆脱了传统文本模态的限制,更加贴近人类的直观交互方式。CogAgent的高分辨率处理能力可达1120×1120像素,具备视觉问答、视觉定位和GUI代理等多种强大功能,并在多项图像理解基准测试中表现出色,显著超越了现有模型如Mind2Web和AITW。
CogAgent是什么
CogAgent是清华大学与智谱AI联合推出的多模态视觉大模型,专注于图形用户界面(GUI)的理解和导航。通过视觉模态对GUI界面进行感知,非传统的文本模态,更符合人类的直觉交互方式。CogAgent能处理高达1120×1120像素的高分辨率图像,具备视觉问答、视觉定位和GUI Agent等多种能力。在多个图像理解基准测试中取得了领先成绩,在GUI操作数据集上显著超越了现有的模型,如 Mind2Web 和 AITW。
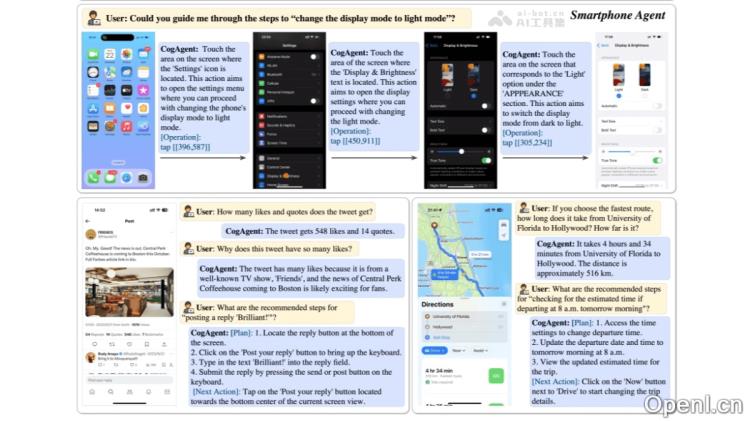
CogAgent的主要功能
- 视觉问答(Visual QA):CogAgent能够针对任意GUI截图进行智能问答,例如解释网页、PPT以及手机软件的功能,甚至能够解读游戏界面。
- 视觉定位(Grounding):模型具备识别和解释小型GUI元素及文本的能力,这对于高效的GUI交互至关重要。
- GUI代理(GUI Agent):CogAgent通过视觉模态对GUI界面进行全面感知,能够进行有效的规划和决策。
- 自动化GUI操作:CogAgent可以模拟用户行为,比如点击按钮、输入文本和选择菜单,提供自动化的GUI操作解决方案。
- 高分辨率处理能力:CogAgent支持高达1120×1120像素的高分辨率图像输入,可以更准确地解析复杂的GUI界面。
- 多模态能力:CogAgent结合了视觉和语言模态,能够在无需API调用的情况下,跨应用和网页执行任务。
CogAgent的技术原理
- 多模态大模型架构:CogAgent基于多模态大模型架构,能够同时处理和解析文本、图像等不同类型的数据。
- 自监督学习技术:CogAgent利用自监督学习技术,在未标注的数据上进行预训练,显著提升了模型的通用性和泛化能力。
- 数据扩充与增强:在预训练阶段,CogAgent通过数据扩充与增强技术,提升了在GUI代理场景下的整体表现。
- 特征提取与融合:CogAgent对多模态数据进行预处理和特征提取,将其转化为模型可理解的格式,并通过深度学习算法进行训练与优化,以准确识别和理解各种模态信息。
CogAgent的项目地址
- Github仓库:https://github.com/THUDM/CogVLM
- HuggingFace模型库:https://huggingface.co/THUDM/cogagent-chat-hf
- arXiv技术论文:https://arxiv.org/pdf/2312.08914
- 魔搭社区:https://modelscope.cn/models/ZhipuAI/cogagent-chat
CogAgent的应用场景
- 自动化测试:CogAgent能够模拟用户操作,对GUI界面进行全面测试,及时发现潜在的界面问题和功能缺陷。
- 智能交互:CogAgent能够理解用户的意图和需求,通过自然语言交互和GUI操作,为用户提供更加智能和便捷的服务。例如在社交软件、游戏等场景中,能够根据用户的指令执行相应操作。
- 多模态人工智能应用开发:CogAgent基于多模态大模型,为AI应用开发提供全新范例。支持图文向量化、大词表目标检测、开放目标检测及多模态大语言模型,适用于工业检测、医学影像分析、自动驾驶、零售商品识别等多种应用场景。
- 企业级AI代理平台:CogAgent可以集成到企业级AI代理平台中,帮助企业用户通过对话的方式提出需求,设计、创建和管理代理,快速定制企业级AI代理以完成各类任务,从而提升工作效率并降低运营成本。
- 智能助理:CogAgent可作为智能助理,辅助企业的日常工作流程,进行智能对话,帮助用户快速了解聊天背景,生成多主题总结,快速回顾每一段对话。
- 多智能体协同:CogAgent的多模态大模型能力能够在多智能体系统中发挥作用,提供设计、生产、物流、销售及服务等全链式智能服务,挖掘数据价值,助力企业利用新技术构筑竞争优势。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...

 粤公网安备 44011502001135号
粤公网安备 44011502001135号