DCLM-7B是一款由苹果公司联合研究团队研发的70亿参数开源小型模型,其性能超过Mistral-7B,接近Llama 3和Gemma。作为DataComp-LM(DCLM)项目的一部分,苹果公司近期在Hugging Face平台发布了该模型,推动了大型语言模型(LLM)开源社区的发展。
DCLM-7B 是什么
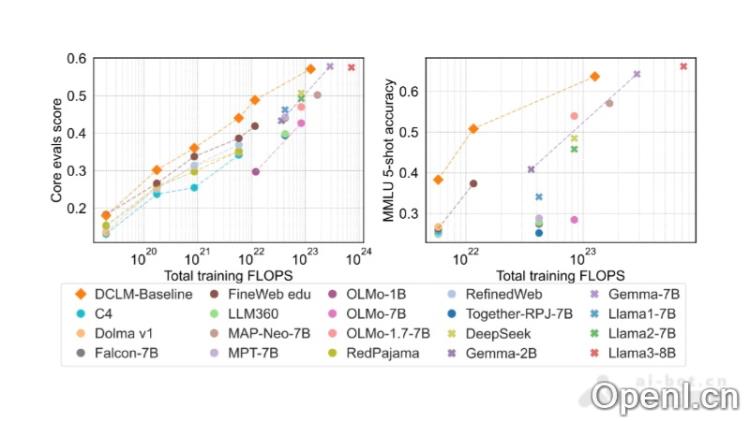
DCLM-7B是一个开源的小型模型,拥有70亿个参数,旨在为研究人员和开发者提供高效的自然语言处理工具。该模型基于240万亿个Common Crawl数据进行训练,使用了标准化的DCLM-POOL和OpenLM框架进行预训练,取得了64%的5-shot MMLU准确率,展现出显著的训练效率。DCLM-7B的开源发布包括模型权重、训练代码和数据集,为数据驱动的模型研究设定了新的基准,尤其是提供了高质量的数据集DCLM-BASELINE。
DCLM-7B 的主要功能
- 丰富的数据支持:DCLM-7B以240万亿个令牌的标准化语料库为基础,确保了模型训练的多样性与丰富性。
- 高效的数据筛选:采用先进的过滤方法,从庞大的数据集中提取出高质量的训练样本,是构建模型的关键。
- 基于OpenLM框架:利用OpenLM框架,DCLM-7B实现了高效的预训练方案,确保了训练流程和超参数设置的标准化。
- 全面的评估体系:在53个下游任务中进行了标准化评估,帮助量化模型的优势与不足。
- 强大的模型架构:采用decoder-only的Transformer架构,适合各种语言模型的深度学习应用。
- 优化的训练流程:使用z-loss等技术,确保输出logit的数值稳定性,提高模型的训练效果。
- 多样化的训练规模:模型在从412M到7B参数的不同计算规模上进行训练,探讨了规模对性能的影响。
产品官网
- 项目网址:https://huggingface.co/apple/DCLM-7B
- GitHub代码库:https://github.com/mlfoundations/dclm
- 技术论文链接:https://arxiv.org/pdf/2406.11794
DCLM-7B 的应用场景
- 人工智能研究者:专注于自然语言处理和机器学习领域的学术人员和研究者。
- 软件开发人员:希望将高级语言处理能力集成到应用程序中的技术专家。
- 数据分析师:负责处理和分析大量文本数据以获取深入见解的专业人士。
- 教育技术专家:致力于开发教育工具和互动学习体验的教育工作者。
- 企业决策者:利用AI技术优化业务流程和提升客户服务的商业领袖。
常见问题
- DCLM-7B的主要优势是什么? DCLM-7B在训练效率和准确性上表现出色,能够处理多种自然语言处理任务。
- 如何获取DCLM-7B模型? 用户可以通过Hugging Face平台或GitHub仓库下载DCLM-7B模型及相关代码。
- 适合哪些项目使用DCLM-7B? DCLM-7B适合用于自然语言处理、机器学习研究、数据分析等多种应用场景。
- 是否有支持和文档? 是的,DCLM-7B的GitHub页面提供了详细的文档和支持信息。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...

 粤公网安备 44011502001135号
粤公网安备 44011502001135号