EzAudio是由约翰霍普金斯大学与腾讯AI实验室合作开发的一款创新性文本到音频(Text-to-Audio,T2A)生成模型。该模型利用高效的扩散变换器技术,能够根据文本提示生成高保真度的音频效果。EzAudio在生成速度、资源效率和音频真实感等方面设定了新的标准,其独特之处在于采用了无分类器引导重缩放技术,从而简化了模型的使用并保持了音频质量。
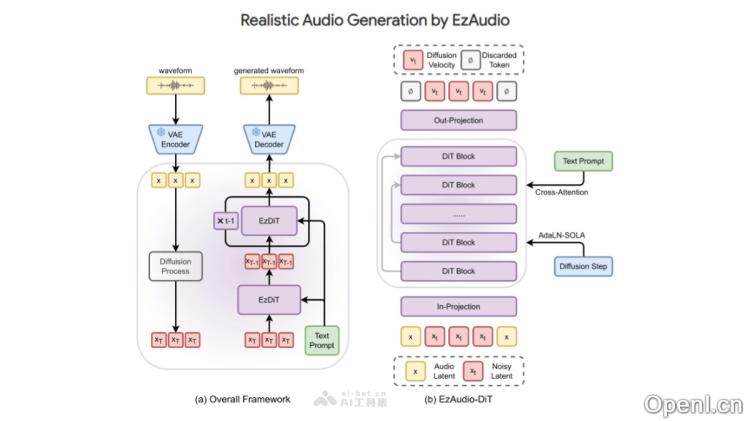
EzAudio的主要功能
- 文本至音频生成:根据用户提供的文本描述生成对应的音频内容。
- 高效性能:优化后的模型架构显著降低了计算资源需求,同时提升了生成速度。
- 优质音频:生成的音频效果具有极高的保真度,能够带来真实的听觉体验。
- 高效训练数据利用:结合未标记与人工标记的数据,有效提升训练效率与模型表现。
EzAudio的技术原理
- 波形变分自动编码器(VAE):采用一维波形VAE处理音频数据,避免了二维频谱图处理的复杂性,降低了计算成本,同时确保了高时间分辨率。
- 优化的扩散变换器架构(EzAudio-DiT):专门设计的扩散模型,包含AdaLN-SOLA和长跳跃连接,以提高模型的参数和内存效率,并保持训练的稳定性。
- 多阶段训练策略:结合自监督学习与监督学习,使用掩码扩散建模和合成字幕数据进行训练,最后在人工标注数据上进行微调,以提升音频生成的准确性和质量。
- 无分类器引导重缩放(CFG Rescaling):在扩散采样过程中调整引导强度,以优化文本与音频的匹配,尽量减少对音频质量的负面影响。
EzAudio的项目地址
- 项目官网:haidog-yaqub.github.io/EzAudio-Page
- GitHub仓库:https://github.com/haidog-yaqub/EzAudio
- 技术论文:https://haidog-yaqub.github.io/EzAudio-Page/static/pdf/ezaudio.pdf
EzAudio的应用场景
- 音乐创作:根据特定的文本描述生成符合特定风格或情感的音乐片段,以辅助音乐人和制作人进行创作。
- 影视后期制作:为电影、电视剧及视频游戏生成真实的音效与配音,增强观众的沉浸感。
- 语音合成:生成标准或特定语调的语音,适用于教育软件、有声读物及语言学习应用。
- 音频编辑:对现有音频进行编辑和修改,无需复杂的音频编辑工具。
- 虚拟助手与聊天机器人:为虚拟助手和聊天机器人生成自然流畅的语音回应。
- 有声内容创作:自动生成有声博客、播客或新闻内容的音频。
常见问题
- EzAudio如何使用?:用户只需输入文本提示,EzAudio便会快速生成相应的音频内容。
- 生成的音频质量如何?:EzAudio生成的音频具有高保真度,能够提供真实的听觉体验。
- 是否需要专业知识才能使用EzAudio?:EzAudio设计简便,即使没有专业背景的用户也能轻松使用。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...

 粤公网安备 44011502001135号
粤公网安备 44011502001135号