Follow Your Pose是一款由清华大学、香港科技大学、腾讯AI Lab及中国科学院的研究团队共同开发并开源的文本到视频生成框架。该系统允许用户通过输入文本描述和指定的人物姿势,生成高度一致且真实感强的视频。其采用了创新的两阶段训练策略,以确保生成的视频在内容和动作上都能与用户的需求相匹配。
Follow Your Pose是什么
Follow Your Pose是一个基于文本与姿态生成视频的开源框架,由清华大学、香港科技大学、腾讯AI Lab和中科院的研究人员联合开发。用户能够通过简单的文本描述及指定的人物姿势,生成与之相符的视频内容。该框架运用了两阶段的训练方法,能够创建出在文本描述和姿态序列上保持高度一致性的视频,同时确保视频中角色动作的自然流畅。
Follow Your Pose的官网入口
- 官方项目主页:https://follow-your-pose.github.io/
- GitHub代码库:https://github.com/mayuelala/FollowYourPose
- Arxiv研究论文:https://arxiv.org/abs/2304.01186
- Hugging Face运行地址:https://huggingface.co/spaces/YueMafighting/FollowYourPose
- OpenXLab运行地址:https://openxlab.org.cn/apps/detail/houshaowei/FollowYourPose
- Google Colab运行地址:https://colab.research.google.com/github/mayuelala/FollowYourPose/blob/main/quick_demo.ipynb
Follow Your Pose的主要功能
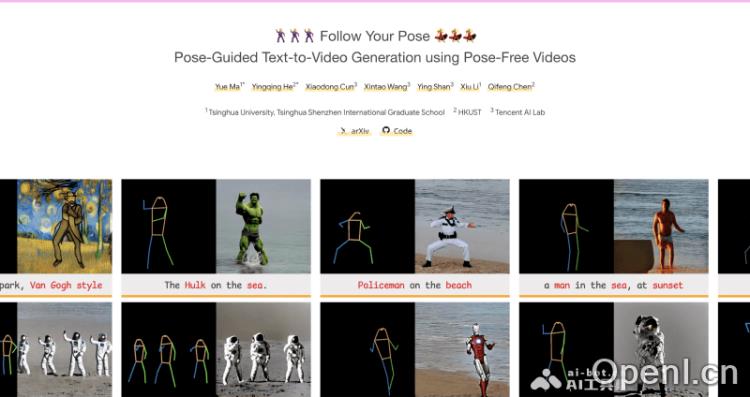
- 文本到视频生成:用户只需输入文本描述,框架即可根据这些信息生成对应的视频内容,包括角色动作、场景背景和整体视觉风格。
- 姿态控制:通过指定人物的姿势序列,用户可以精准控制视频中角色的每一个动作细节。
- 时间连贯性:生成的视频能够保持时间上的连贯性,确保动作和场景变化自然流畅,无突兀的跳跃或闪烁。
- 多样化角色与背景生成:框架支持生成多种风格和外观的视频,包括现实主义、卡通和赛博朋克等风格。
- 多角色视频生成:支持在同一视频中展示多个角色,用户可根据文本描述指定每个角色的身份与动作。
- 风格化视频生成:用户可以通过添加风格描述,生成具有特定艺术风格的视频。
Follow Your Pose的工作原理
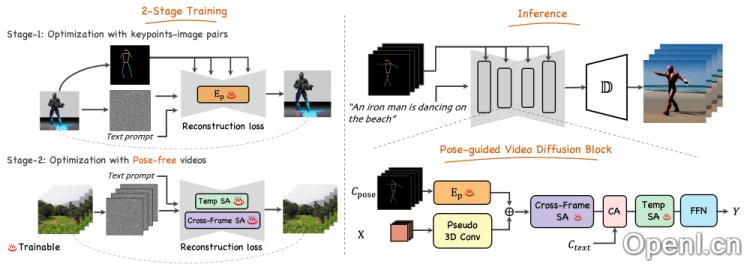
Follow Your Pose的工作流程基于两阶段的训练过程,旨在将文本描述与姿态信息结合,生成视频。以下为其详细步骤:
- 第一阶段:姿态控制的文本到图像生成
- 姿态编码器:框架首先利用零初始化的卷积编码器来提取输入姿态序列中的关键点特征。
- 特征注入:提取的姿态特征被下采样至不同分辨率,并通过残差连接方式注入到预训练的文本到图像(T2I)模型的U-Net结构中,以实现姿态控制。
- 训练:在这一阶段,模型仅使用姿态图像对进行训练,旨在学习如何根据文本描述和姿态信息生成图像。
- 第二阶段:视频生成
- 视频数据集:为了学习时间连贯性,框架在这一阶段使用未标注姿态的高清视频数据集进行训练。
- 3D网络结构:将预训练的U-Net模型扩展为3D网络,以处理视频输入,涉及将第一层卷积扩展为伪3D卷积,并添加时间自注意力模块。
- 跨帧自注意力:引入跨帧自注意力模块,以增强视频帧之间的内容一致性。
- 微调:在此阶段,仅与时间连贯性相关的参数进行更新,其余参数保持不变。
- 生成过程
- 文本和姿态输入:推理阶段,用户输入描述角色外观及动作的文本和姿势序列。
- 视频生成:模型根据输入生成视频,大部分预训练的稳定扩散模型参数被冻结,仅与时间连贯性相关的模块参与计算。
通过这种创新的两阶段训练策略,Follow Your Pose能够从易获取的数据集中有效学习,生成高度可控且时间连贯的视频。
应用场景
Follow Your Pose可以广泛应用于游戏开发、动画制作、教育培训、广告宣传等多个领域。用户能够根据具体需求定制视频内容,为创意工作提供强有力的支持。
常见问题
1. Follow Your Pose是否免费使用?
是的,Follow Your Pose是开源的,用户可以自由使用和修改。
2. 我需要编程知识才能使用Follow Your Pose吗?
不需要,Follow Your Pose提供了用户友好的界面和文档,使其易于上手。
3. 生成的视频质量如何?
Follow Your Pose能够生成高质量且时间连贯的视频,确保视觉体验良好。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...

 粤公网安备 44011502001135号
粤公网安备 44011502001135号