FunAudioLLM是阿里巴巴通义实验室推出的一款创新开源语音大模型项目,旨在提供高效的语音识别与生成解决方案。该项目包含SenseVoice和CosyVoice两个核心模型,前者专注于多语言语音识别和情感分析,支持超过50种语言,尤其在中文和粤语表现卓越;后者则致力于自然语音生成,能够调控音色与情感,支持中文、英语、日语、粤语和韩语。
FunAudioLLM是什么
FunAudioLLM是阿里巴巴通义实验室推出的一款开源语音大模型项目,旨在满足多样化的语音识别和生成需求。该项目包括两个主要模型:SenseVoice和CosyVoice。SenseVoice擅长于多语言的语音识别和情感识别,支持50多种语言,尤其在中文和粤语上表现尤为出色。而CosyVoice则专注于自然流畅的语音生成,能够在多个语言环境中灵活应用,支持音色和情感的精细控制。FunAudioLLM广泛适用于多语言翻译、情感互动对话等多个场景。相关模型与代码已在Modelscope和Huggingface平台上开源。
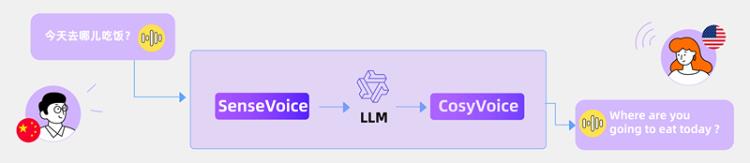
FunAudioLLM的主要功能
- SenseVoice模型:
- 提供高精度的多语言语音识别能力。
- 支持超过50种语言,尤其在中文和粤语的识别效果上超越现有技术。
- 具备情感识别的功能,能够识别多种人机交互中的情绪状态。
- 根据需求提供轻量级和大型版本,适用于不同的应用场景。
- CosyVoice模型:
- 专注于自然语音生成,支持多种语言,并可调节音色与情感。
- 能够利用少量原始音频快速生成高度相似的音色,包括韵律和情感细节。
- 支持跨语言的语音生成和精细的情感控制。

FunAudioLLM的项目地址
- 项目官网:https://fun-audio-llm.github.io/
- CosyVoice 在线体验:https://www.modelscope.cn/studios/iic/CosyVoice-300M
- SenseVoice 在线体验:https://www.modelscope.cn/studios/iic/SenseVoice
- GitHub仓库:https://github.com/FunAudioLLM
- arXiv技术论文:https://arxiv.org/abs/2407.04051
FunAudioLLM的应用场景
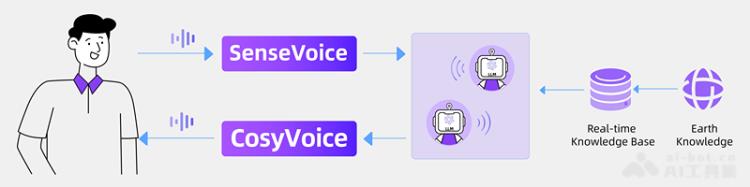
- 开发者和研究人员:利用FunAudioLLM进行语音识别、合成及情感分析等领域的研究和技术开发。
- 企业用户:在客户服务、智能助手及多语言翻译等场景中应用FunAudioLLM,以提升工作效率与用户体验。
- 内容创作者:借助FunAudioLLM生成有声读物或播客,丰富内容形式,吸引更广泛的听众。
- 教育领域:用于语言学习和听力训练等教育应用,提升学习的有效性和趣味性。
- 残障人士:帮助视障人士通过语音交互获取信息,改善日常生活便利性。
常见问题
有关FunAudioLLM的更多问题和解答请访问我们的官网或GitHub仓库,我们将定期更新常见问题解答以帮助用户更好地使用我们的产品。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...

 粤公网安备 44011502001135号
粤公网安备 44011502001135号