GTSinger是一个由浙江大学研究团队开发的大型开源高质量歌声数据集,旨在支持多种歌声任务。该数据集包含80.59小时的专业录音棚录制的歌声,涵盖九种语言,包括汉语、英语、日语、韩语、俄语、西班牙语、法语、德语和意大利语,由20位专业歌手演唱,展现出丰富的音色和风格多样性。
GTSinger是什么
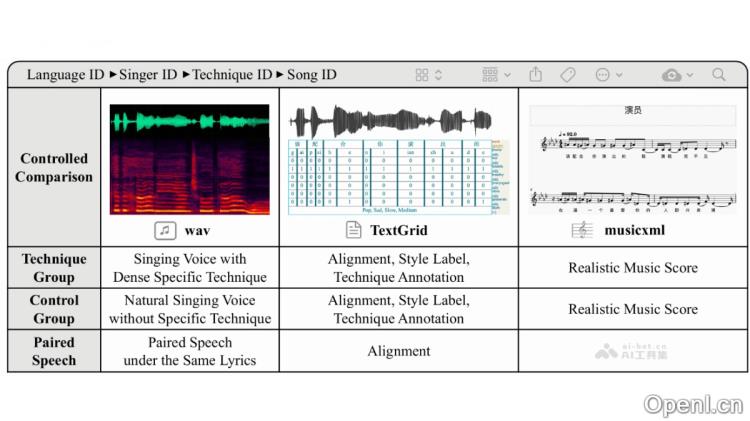
GTSinger是浙江大学研究团队推出的一款大型开源高质量歌声数据集,专注于支持多元化的歌声相关任务。该数据集包含80.59小时的专业录音棚录制的歌声,覆盖九种不同的语言,包括汉语、英语、日语、韩语、俄语、西班牙语、法语、德语和意大利语,所有录音均由20位专业歌手演唱,呈现出丰富多彩的音色与风格。GTSinger特别关注歌唱技巧的控制与建模,提供六种常用歌唱技巧的对照组和音素级标注,并附有真实乐谱,便于实际音乐创作。数据集还包括人工音素对齐、全局风格标签及配对朗读数据,适应各种歌声任务。
GTSinger的主要功能
- 多语言歌声数据集:GTSinger提供九种不同语言的歌声,支持跨语言的歌声合成与分析,展现多样的音色和风格。
- 歌唱技巧控制:该数据集提供六种常用歌唱技巧的对照组和音素级标注,帮助研究者更好地建模和控制歌声中的技巧。
- 真实乐谱支持:伴随歌声提供匹配的真实乐谱,为歌声合成技术在实际音乐创作中的应用提供便利。
- 多任务适配:GTSinger设计支持多种歌声任务,包括歌声合成、技巧识别、风格迁移及语音转歌声等。
- 基准测试:数据集提供基准测试,用于评估在不同歌声任务下的表现和适用性。
GTSinger的技术原理
- 高质量音频录制:GTSinger的数据集在专业录音棚中录制,确保音频数据的高品质。
- 音素对齐与标注:应用音乐信息检索技术(如MFA和Praat)进行音素对齐与标注,实现音素级的精确控制。
- 歌唱技巧标注:通过专家听感和音频分析技术对歌声中的歌唱技巧进行标注,便于模型学习与控制。
- 乐谱生成:结合音频信号处理技术与音乐理论,从歌声中提取音高信息,生成MIDI形式的乐谱,并由专家调整为真实乐谱。
- 数据集构建与验证:通过人工审核和后期处理,确保数据集的质量与适用性,包括音频片段的语义分割和无声区域的处理。
GTSinger的项目地址
- 项目官网:gtsinger.github.io
- GitHub仓库:https://github.com/GTSinger/GTSinger
- HuggingFace模型库:https://huggingface.co/datasets/GTSinger/GTSinger
- arXiv技术论文:https://arxiv.org/pdf/2409.13832
GTSinger的应用场景
- 歌声合成:基于数据集中的歌声样本和技巧标注,开发出合成特定技巧和风格的高质量歌声的系统。
- 歌声技巧识别:分析歌声中的音素级技巧标注,训练模型识别与分类不同的歌声技巧。
- 歌声风格迁移:将一种风格的歌声转换为另一种风格,例如将流行歌曲的歌声转化为古典风格。
- 语音转歌声(Speech-to-Singing,STS):将普通语音转化为旋律化的歌声,应用于语音合成和音乐创作。
- 音乐教育:利用数据集中的真实乐谱和歌声样本,开发音乐教育工具,帮助学生学习与练习唱歌技巧。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...

 粤公网安备 44011502001135号
粤公网安备 44011502001135号