HourVideo是斯坦福大学李飞飞及吴佳俊团队联合推出的一个长视频理解基准数据集。它包含500段第一人称视角的视频,时长介于20分钟到120分钟之间,涵盖了77种日常活动,旨在评估多模态模型在长视频理解方面的能力。
HourVideo是什么
HourVideo是由斯坦福大学的李飞飞和吴佳俊团队推出的长视频理解基准数据集,包含500个第一人称视角的视频,时长从20分钟到120分钟不等,涵盖77种日常活动。这一数据集旨在通过一系列任务(如总结、感知、视觉推理和导航)来测试模型对多个时间片段信息的识别与综合能力,以推动长视频理解技术的进步。
HourVideo的主要功能
- 长视频理解评测:HourVideo专注于测试模型对长达一小时视频的视觉数据流的理解能力。
- 多任务评估套件:数据集涵盖多种任务,如总结、感知、视觉推理和导航,全面考察模型在不同视频语言理解方面的表现。
- 高质量问题生成:基于人工注释者和大型语言模型(LLMs)生成的12,976个多项选择题,为测试提供标准化的题目。
- 模型性能比较:与其他多模态模型进行比较,评估不同模型在长视频理解任务中的表现。
HourVideo的技术原理
- 视频数据集构建:HourVideo从Ego4D数据集中挑选出500个第一人称视角的视频,涵盖日常活动,视频时长从20分钟到120分钟不等。
- 任务套件设计:设计包含多个子任务的任务套件,确保每个任务都要求模型对视频内容进行长期依赖关系的理解和推理。
- 问题原型开发:为每个任务设计问题原型,确保回答问题时需要对视频的多个时间片段进行信息识别和综合。
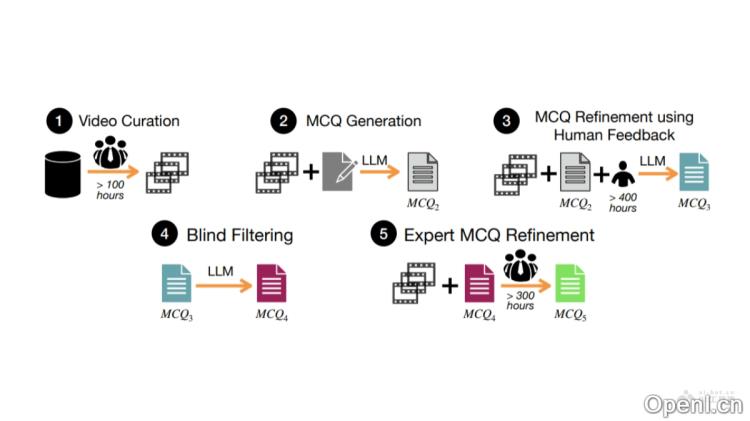
- 数据生成流程:基于多阶段的数据生成流程,包括视频筛选、问题生成、人工反馈优化、盲筛选及专家优化,确保生成高质量的多项选择题。
HourVideo的项目地址
- arXiv技术论文:https://arxiv.org/pdf/2411.04998v1
HourVideo的应用场景
- 多模态人工智能研究:用于研究和开发理解长时间连续视频内容的多模态模型。
- 自主代理和助手系统:推动开发能够理解长时间视觉信息并做出决策的自主代理和虚拟助手。
- 增强现实(AR)和虚拟现实(VR):为创建能理解用户行为并做出相应的沉浸式AR/VR体验提供技术支持。
- 视频内容分析:对监控视频、新闻报道、教育视频等进行分析,提取关键信息和洞察。
- 机器人视觉:帮助机器人理解长时间序列的视觉信息,提升其在复杂环境中的导航和操作能力。
常见问题
- HourVideo的目标是什么? HourVideo旨在评估多模态模型在长视频理解中的性能,推动相关技术的发展。
- HourVideo包含多少个视频? 数据集中包含500个第一人称视角的视频,时长从20分钟到120分钟不等。
- 该数据集适合哪些研究领域? HourVideo适用于多模态人工智能研究、自主代理、AR/VR、视频内容分析和机器人视觉等多个领域。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...

 粤公网安备 44011502001135号
粤公网安备 44011502001135号