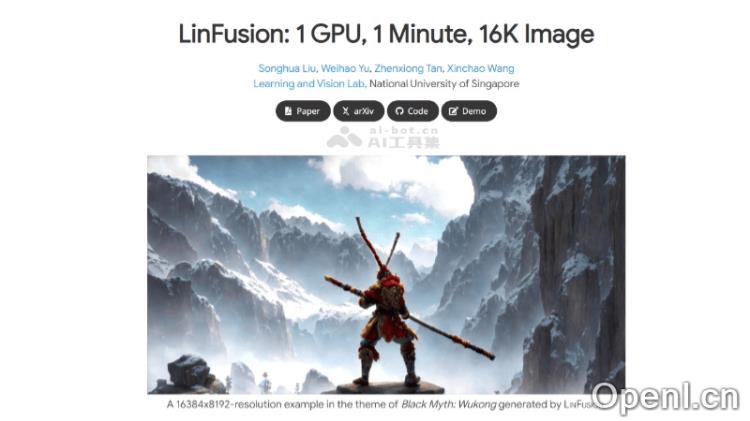
LinFusion 是新加坡国立大学研究团队开发的一款创新图像生成模型,采用线性注意力机制,专门针对高分辨率图像生成任务进行优化。该模型在处理大规模像素数据时,保持线性计算复杂度,从而显著提升了生成效率。LinFusion 现有的预训练模型组件如 ControlNet 和 IP-Adapter 高度兼容,支持零样本跨分辨率生成,能够在未见过的分辨率上生成图像。它在单个 GPU 上实现高达 16K 分辨率的图像生成,为艺术创作、游戏设计和虚拟现实等多个领域提供强大的视觉内容生成能力。
LinFusion是什么
LinFusion 是由新加坡国立大学的研究团队所开发的一款前沿图像生成模型,利用线性注意力机制处理高分辨率图像生成。该模型在处理大量像素时保持线性计算复杂度,显著提高了生成效率。LinFusion 的预训练模型组件如 ControlNet 和 IP-Adapter 高度兼容,支持在未见过的分辨率下进行零样本跨分辨率图像生成。它能够在单个 GPU 上生成高达 16K 分辨率的图像,极大地满足了艺术创作、游戏设计和虚拟现实等领域的需求。
LinFusion的主要功能
- 文本到图像生成:根据用户输入的文本描述,快速生成对应的高分辨率图像。
- 高分辨率支持:专为生成高分辨率图像而优化,包括在训练期间未遇到的分辨率。
- 线性复杂度:通过线性注意力机制,提高计算效率,减少资源消耗。
- 跨分辨率生成:支持在不同分辨率下生成图像,包括未在训练中见过的分辨率。
- 兼容预训练组件:与预训练的 Stable Diffusion 组件(如 ControlNet 和 IP-Adapter)兼容,无需额外的训练即可直接使用。
LinFusion的技术原理
- 线性注意力机制:LinFusion 引入了一种新颖的线性注意力机制,区别于传统 Transformer 模型的二次复杂度自注意力。这一机制使得模型在处理大量像素时,计算复杂度与像素数量的关系为线性,从而有效降低资源需求。
- 广义线性注意力:LinFusion 采用广义线性注意力框架,扩展了现有的线性复杂度标记混合器(如 Mamba、Mamba2 和 Gated Linear Attention)。这一机制结合了归一化感知和非因果操作,以满足高分辨率视觉生成的需求。
- 归一化感知:归一化感知注意力机制确保每个 token 的注意力权重之和为 1,使模型在不同尺度的图像上表现一致。
- 非因果性:非因果版本的线性注意力机制允许模型在生成过程中同时访问所有噪声空间标记,而非像传统 RNN 那样顺序处理,有助于更好地捕捉图像的空间结构。
LinFusion的项目地址
- 项目官网:lv-linfusion.github.io
- GitHub仓库:https://github.com/Huage001/LinFusion
- arXiv技术论文:https://arxiv.org/pdf/2409.02097
LinFusion的应用场景
- 艺术创作:艺术家和设计师可以利用 LinFusion 根据文本描述生成高分辨率艺术作品,极大地加速创作过程。
- 游戏开发:在游戏设计中,LinFusion 能够快速生成游戏场景、角色或概念艺术,提升美术制作的效率。
- 虚拟现实(VR)和增强现实(AR):在 VR 或 AR 内容创建中,LinFusion 有助于生成逼真的背景图像或环境,增强用户体验。
- 电影和视频制作:电影制作者可以使用 LinFusion 生成场景概念图或特效背景,缩短前期制作时间。
- 广告和营销:营销团队利用 LinFusion 快速生成引人注目的广告图像和社交媒体帖子,提升营销内容的吸引力。
常见问题
- LinFusion支持哪些类型的输入?:LinFusion 主要支持文本描述作为输入,生成相应的图像。
- 需要多少计算资源才能运行LinFusion?:LinFusion 在单个 GPU 上即可运行,并支持高达 16K 的图像生成。
- LinFusion可以用于哪些行业?:LinFusion 可广泛应用于艺术创作、游戏开发、虚拟现实、电影制作及广告营销等多个领域。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...

 粤公网安备 44011502001135号
粤公网安备 44011502001135号