LLaVA-OneVision是一款由字节跳动推出的开源多模态人工智能模型,能够同时处理单图像、多图像和视频场景下的计算机视觉任务。该模型通过整合数据、模型和视觉表示的深刻见解,展现出卓越的跨模态迁移学习能力,尤其在图像到视频的任务转移中表现尤为突出,具备强大的视频理解和跨场景处理能力。
LLaVA-OneVision是什么
LLaVA-OneVision是字节跳动开发的开源多模态AI模型,旨在整合不同类型的数据和视觉表示,以高效处理单一图像、多图像及视频内容的计算机视觉任务。其跨模态和跨场景的迁移学习能力使得它在图像到视频的任务转移中表现出色,具备卓越的视频理解与跨场景适应能力。
LLaVA-OneVision的主要功能
- 多模态理解:具备处理单一及多重图像和视频内容的能力,提供深入的视觉分析。
- 任务迁移:支持不同视觉任务之间的迁移学习,特别是在图像转视频的任务迁移中展现出色的理解能力。
- 跨场景能力:在多种视觉场景下展现强大的适应性,支持图像分类、识别及描述生成等多种任务。
- 开源贡献:模型开源,提供代码库、预训练权重及多模态指令数据,促进研究与应用的快速发展。
- 高性能:在多个基准测试中超越现有模型,表现出卓越的性能和良好的泛化能力。
LLaVA-OneVision的技术原理
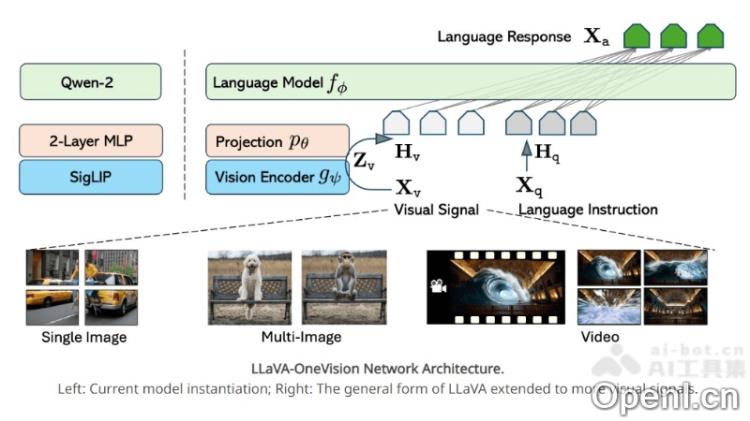
- 多模态架构:采用多模态架构,将视觉信息与语言信息进行融合,以全面理解和处理多样的数据类型。
- 语言模型集成:选用Qwen-2作为语言模型,具备强大的语言理解与生成能力,能准确解读用户输入并生成高质量文本。
- 视觉编码器:使用Siglip作为视觉编码器,在图像和视频特征提取方面表现优异,能够捕捉关键视觉信息。
- 特征映射:通过多层感知机(MLP)将视觉特征映射到语言嵌入空间,为多模态融合提供桥梁。
- 任务迁移学习:允许在不同模态或场景间进行任务迁移,使模型能够发展新的能力和应用。
LLaVA-OneVision的项目地址
- GitHub仓库:https://llava-vl.github.io/blog/2024-08-05-llava-onevision/
- arXiv技术论文:https://arxiv.org/pdf/2408.03326
如何使用LLaVA-OneVision
- 环境准备:确保具备适合的计算环境,包括必要的硬件资源及软件依赖。
- 获取模型:访问LLaVA-OneVision的GitHub仓库,下载或克隆模型的代码库和预训练权重。
- 安装依赖:根据项目文档安装所需的依赖库,如深度学习框架(例如PyTorch或TensorFlow)及其他相关库。
- 数据准备:准备或获取希望模型处理的数据,如图像、视频或多模态数据,并按照模型要求格式化数据。
- 模型配置:根据具体应用场景配置模型参数,包括调整模型的输入输出格式及学习率等超参数。
LLaVA-OneVision的应用场景
- 图像和视频分析:用于深入分析图像和视频内容,包括物体识别、场景理解和图像描述生成等。
- 内容创作辅助:为艺术家和创作者提供灵感和素材,帮助创作图像、视频等多媒体内容。
- 聊天机器人:作为聊天机器人,与用户进行流畅的自然对话,提供信息查询和娱乐互动等服务。
- 教育和培训:在教育领域中辅助教学,提供视觉辅助材料,提升学习体验。
- 安全监控:在安全领域分析监控视频,识别异常行为或事件,提高安全监控的效率。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...

 粤公网安备 44011502001135号
粤公网安备 44011502001135号