LMMs-Eval 是一个专为多模态人工智能模型而设计的全面评估框架,致力于提供标准化且高效的模型性能评估解决方案。它涵盖了50多个任务和10多种模型,通过透明且可复现的评估流程,帮助研究人员和开发者深入了解模型的能力。通过引入 LMMs-Eval Lite 和 LiveBench,LMMs-Eval 不仅降低了评估成本,还通过动态更新评估数据集,提供了更为精准的模型泛化能力评估。
LMMs-Eval是什么
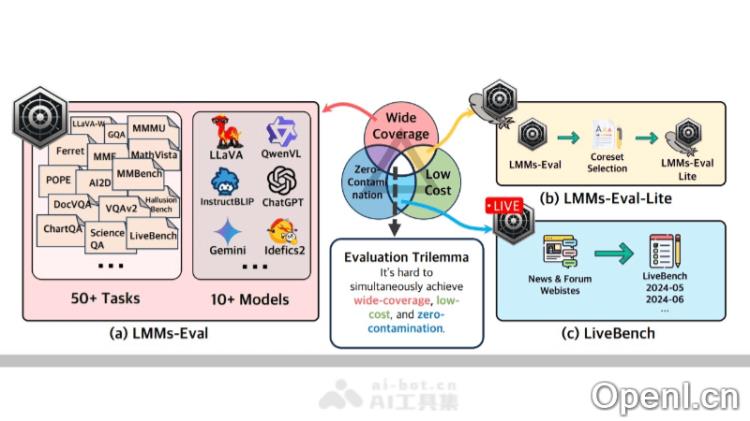
LMMs-Eval 是一个多模态 AI 模型的统一评估框架,旨在通过标准化和高效的方式对模型性能进行评估。它包含了超过50个任务和10多种模型,为研究人员和开发者提供了一个透明且可复现的评估流程,以全面了解模型的处理能力。此外,LMMs-Eval 引入了 LMMs-Eval Lite 和 LiveBench,前者通过简化数据集来降低评估成本,后者则通过实时网络信息动态更新评估数据集,以无污染的方式考察模型的泛化能力。这为多模态模型的进一步发展提供了重要的评估工具。

LMMs-Eval的主要功能
- 统一评估工具:提供标准化的评估流程,支持对超过50个任务和10多种模型的综合性评估。
- 透明性和可复现性:确保评估结果的透明性和可复现性,便于研究人员验证和比较不同模型的性能。
- 广泛的任务覆盖:涵盖图像理解、视觉问答、文档分析等多种任务类型,全面考察模型的多模态处理能力。
- 低成本评估选项:通过 LMMs-Eval Lite 提供精简的评估工具包,减少数据集规模,从而降低评估成本,同时保持评估质量。
LMMs-Eval的技术原理
- 标准化评估程序:定义统一的接口和评估协议,使研究人员能够在相同基准下测试和比较不同模型的性能。
- 多任务处理能力:框架设计可以同时处理多种类型的任务,包括图像和语言的理解与生成。
- 数据集选择与核心集提取:LMMs-Eval 利用算法选择代表性数据子集,以减少评估资源的消耗,同时保证评估结果的一致性和可靠性。
- 动态数据收集机制:LiveBench 组件通过自动收集互联网上最新的新闻和论坛信息,生成动态更新的评估数据集。
- 防污染机制:通过分析训练数据与评估基准数据的重叠,LMMs-Eval 能识别和减少数据污染,确保评估的有效性。
LMMs-Eval的项目地址
- 项目官网:https://lmms-lab.github.io/
- GitHub仓库:https://github.com/EvolvingLMMs-Lab/lmms-eval
- arXiv技术论文:https://arxiv.org/pdf/2407.12772
如何使用LMMs-Eval
- 获取代码:从 GitHub 仓库克隆 LMMs-Eval 的代码库到本地环境。
- 安装依赖项:安装所需的依赖,包括 Python 包和可能的系统依赖。
- 选择模型和数据集:根据评估需求,从支持的模型和数据集中选择相应的模型和任务。
- 配置评估参数:根据所选模型和数据集,设置评估参数,包括指定模型权重、数据路径和评估类型。
- 运行评估:使用 LMMs-Eval 提供的命令行工具或 Python 脚本启动评估过程,执行标准化的评估流程并生成结果。
LMMs-Eval的应用场景
- 学术研究:研究人员可以利用 LMMs-Eval 评估和比较不同大型多模态模型在多种任务上的表现,例如图像识别、自然语言处理和跨模态理解。
- 工业应用测试:在多模态 AI 应用开发中,LMMs-Eval 可用于全面测试模型,以确保满足特定业务需求。
- 模型开发与迭代:在模型开发的每个阶段,LMMs-Eval 可帮助开发者快速评估模型改进,进行调优和迭代。
- 教育和培训:教育机构可以将 LMMs-Eval 作为教学工具,帮助学生理解多模态模型的工作原理和评估方法。
- 竞赛与基准测试:在 AI 竞赛中,LMMs-Eval 可作为标准化评估平台,确保不同参赛团队在相同基准下进行公平比较。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...

 粤公网安备 44011502001135号
粤公网安备 44011502001135号