LongVU是一款由Meta AI团队开发的先进长视频理解模型,采用时空自适应压缩技术,旨在应对传统大型语言模型(LLM)在处理长视频时的上下文限制。通过跨模态查询和帧间依赖性分析,LongVU能够有效减少视频标记数量,同时保留长视频中的关键视觉细节。
LongVU是什么
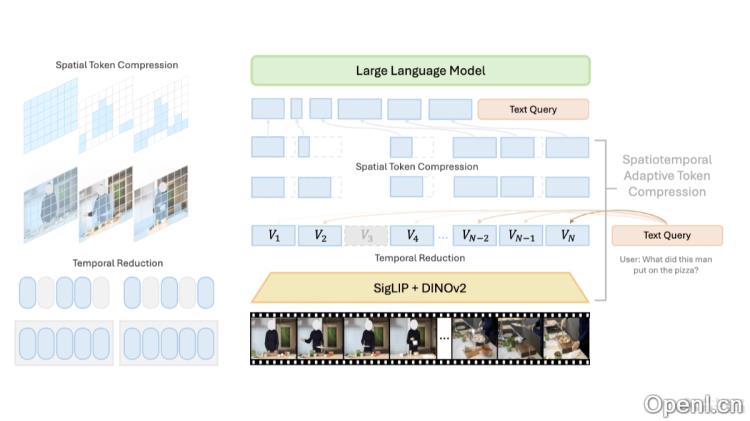
LongVU是Meta AI团队推出的长视频理解模型,利用时空自适应压缩机制,专为解决大型语言模型在处理长视频时的上下文大小限制而设计。该模型通过跨模态查询和帧间依赖性分析,能够在减少视频标记数量的同时,保持长视频中的重要视觉信息。LongVU采用DINOv2特征去除冗余相似帧,同时通过文本引导的跨模态查询进行选择性特征降低,以实现必要时的空间标记压缩。LongVU能够高效处理大量视频帧,并在给定的上下文长度范围内,尽可能减少视觉信息的损失。
LongVU的主要功能
- 时空自适应压缩:通过减少视频标记数量,LongVU能够在有限的上下文长度内有效处理长视频内容,同时保留重要的视觉细节。
- 跨模态查询:利用文本引导的跨模态查询,LongVU可以选择性地保留与文本查询最相关的帧信息,将其他帧降低到低分辨率标记表示。
- 帧间依赖性分析:LongVU通过分析视频帧之间的时间依赖性,能够在必要时进行空间标记的压缩,从而降低模型对上下文长度的需求。
- 长视频理解:LongVU支持处理1fps采样的视频输入,并能将每小时长视频的平均每帧标记数量适应性地减少到2个,符合8k上下文长度的多模态大型语言模型(MLLM)的要求。
LongVU的技术原理
- 时间压缩策略:通过DINOv2特征识别并去除高度相似的冗余帧,LongVU在时间维度上减少冗余。
- 选择性特征降低:基于文本引导的跨模态查询,LongVU保留与文本查询相关的帧的完整标记,而对其他帧应用空间池化,减少空间维度上的冗余。
- 空间标记压缩:对于特别长的视频,LongVU依据帧间的时间依赖性进一步压缩空间标记,计算帧间的空间标记相似性,剔除与首帧相似度过高的后续帧的空间标记,从而降低模型需处理的数据量。
- 多模态训练:LongVU结合图像-语言预训练和视频-语言微调,通过大规模视频-文本对进行训练,提升模型在视频理解任务中的表现。
LongVU的项目地址
- 项目官网:vision-cair.github.io/LongVU
- GitHub仓库:https://github.com/Vision-CAIR/LongVU
- HuggingFace模型库:https://huggingface.co/collections/Vision-CAIR/longvu-67181d2debabfc1eb050c21d
- arXiv技术论文:https://arxiv.org/pdf/2410.17434
- 在线体验Demo:https://huggingface.co/spaces/Vision-CAIR/LongVU
LongVU的应用场景
- 视频内容分析:LongVU可用于分析长视频内容,提取重要信息,例如在监控视频、新闻报道或纪录片中识别关键事件和场景。
- 视频搜索与索引:基于对视频内容的理解,LongVU能够帮助构建视频搜索引擎,使用户通过文本查询快速定位视频中的相关片段。
- 视频内容生成:LongVU可用于生成视频内容的描述、总结或字幕,从而提升视频内容的可访问性和无障碍性。
- 视频问答系统:LongVU支持构建视频问答系统,用户可以针对视频内容提出问题,系统能够理解并提供准确的答案。
- 教育和培训:在教育领域,LongVU可用于分析教学视频,提取关键学习点,帮助学生更好地理解和掌握课程内容。
常见问题
- LongVU的工作原理是什么?LongVU通过时空自适应压缩技术,结合跨模态查询和帧间依赖性分析,能够高效处理长视频,并尽量减少视觉信息的损失。
- LongVU适用于哪些类型的视频?LongVU适用于各种类型的长视频,包括监控视频、纪录片、教育视频等,能够提取关键信息并生成相关内容。
- 我可以在哪里找到LongVU的代码和模型?您可以访问LongVU的GitHub仓库和HuggingFace模型库,获取相关代码和模型。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...

 粤公网安备 44011502001135号
粤公网安备 44011502001135号