MaskGCT是一款由趣丸科技与香港中文大学(深圳)联合开发的先进语音合成大模型。该产品基于掩码生成模型及语音表征解耦编码技术,能够在声音克隆、跨语言合成和语音控制等多项任务中展现出卓越的性能。其在多个语音合成基准数据集上达到了行业领先的水平,某些指标更是超越了人类的表现。
MaskGCT是什么
MaskGCT是趣丸科技与香港中文大学(深圳)合作开发的一款前沿语音合成大模型。凭借掩码生成模型和语音表征解耦编码技术的支持,该模型在声音克隆、跨语言合成和语音控制等领域取得了显著成效。MaskGCT能够迅速且真实地复刻多种音色,灵活调整语音的持续时间、速度与情感,支持中文、英文、日文、韩文、法文和德文等六种语言的合成。该模型已在Amphion系统中开源,面向全球用户开放使用。
MaskGCT的主要功能
- 声音克隆:能够迅速复制任何音色,包括人类声音和动漫角色,完整再现语调、风格与情感。
- 跨语言合成:支持多种语言的语音生成,包括中文、英文、日文、韩文、法文和德文,实现无缝的跨语言输出。
- 语音控制:可灵活调整生成语音的长度、速度和情感,通过编辑文本来控制语音内容,同时保持韵律和音色的一致性。
- 高质量语音数据集:基于高质量的多语言语音数据集Emilia进行训练,提供丰富的语音合成资源。
MaskGCT的技术原理
- 语音语义表示编解码器:将语音转换为语义标记,利用VQ-VAE模型学习向量量化码本,从自监督学习模型中重建语音的语义表示。
- 语音声学编解码器:将语音波形量化为多层离散标记,保留语音信息,并采用RVQ方法压缩语音波形,使用Vocos架构作为解码器。
- 文本到语义模型:基于非自回归掩码生成Transformer,独立于文本到语音的对齐信息,通过语言模型的上下文学习能力预测语义标记。
- 语义到声学模型:同样使用非自回归掩码生成Transformer,语义标记作为条件生成多层声学标记序列,重建高质量的语音波形。
MaskGCT的项目地址
- GitHub仓库:https://github.com/open-mmlab/Amphion/tree/main/models/tts/maskgct
- HuggingFace模型库:https://huggingface.co/amphion/MaskGCT
- arXiv技术论文:https://arxiv.org/pdf/2409.00750v2
- 公测版地址(趣丸千音):https://voice.funnycp.com/
MaskGCT的应用场景
- 有声读物和播客:利用MaskGCT生成的高质量语音,为电子书、有声读物和播客节目提供自然动听的朗读声,提升听众的听觉体验。
- 智能助手和聊天机器人:在智能设备及客服系统中,MaskGCT为用户提供更加自然和个性化的语音交互体验。
- 视频游戏和虚拟现实:在游戏及虚拟现实应用中,MaskGCT为角色生成逼真的语音,增强用户的沉浸感。
- 影视制作和配音:在影视后期制作中,MaskGCT能够快速生成或替换角色的语音,提高制作效率。
- 语言学习和教育:MaskGCT可以生成标准或特定口音的语音,辅助语言学习者进行发音和听力的练习。
常见问题
- MaskGCT支持哪些语言? MaskGCT支持中文、英文、日文、韩文、法文和德文六种语言的语音合成。
- 如何使用MaskGCT? 用户可以访问公测版地址进行试用,开发者也可通过GitHub仓库获取源代码。
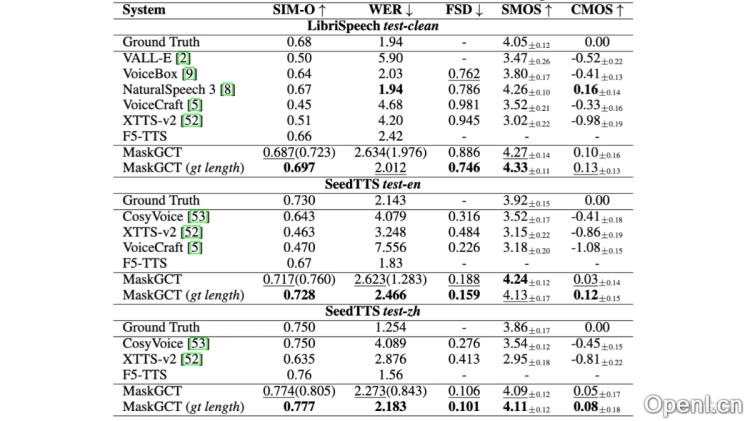
- MaskGCT的音质如何? MaskGCT在多个TTS基准数据集上表现优异,高质量的语音合成效果甚至超过了人类。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...

 粤公网安备 44011502001135号
粤公网安备 44011502001135号