Mini-LLaVA是一款由清华大学与北京航空航天大学的研究团队共同研发的轻量级多模态大语言模型。该模型能够高效处理图像、文本及视频输入,适用于复杂的视觉-文本关联任务。基于Llama 3.1模型,Mini-LLaVA经过优化,可以在单个GPU上运行,方便研究者和开发者使用。
Mini-LLaVA是什么
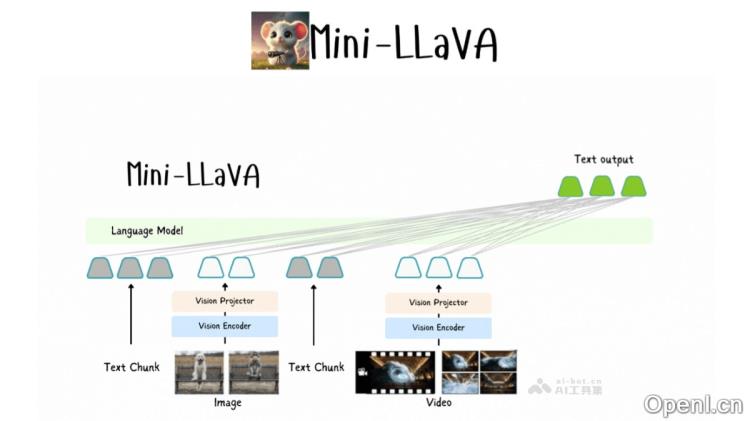
Mini-LLaVA是一款轻量级的多模态大语言模型,由清华大学和北京航空航天大学的研究团队联合开发。该模型具有处理图像、文本和视频输入的能力,实现了高效的多模态数据处理。基于Llama 3.1模型,Mini-LLaVA采用优化的代码结构,使其能够在单个GPU上运行,特别适合复杂的视觉-文本关联任务。项目已在GitHub上开源,便于研究人员和开发者进行下载和使用。Mini-LLaVA在设计上注重代码的可读性和功能的扩展性,支持定制和微调,以适应不同的应用场景。
Mini-LLaVA的主要功能
- 图像理解:模型可以分析图像内容,并根据这些内容生成描述或回答相关问题。
- 视频分析:Mini-LLaVA能够处理视频数据,理解视频内容并提供相应的文本输出。
- 文本生成:基于输入的图像或视频,模型可以生成相应的文本描述或总结。
- 视觉-文本关联:模型能够理解图像与文本之间的关系,并在生成的文本中体现这种关联。
- 灵活性:由于其轻量级的特性和简化的代码结构,Mini-LLaVA可以在资源有限的环境中部署,例如单个GPU。
Mini-LLaVA的技术原理
- 多模态输入处理:Mini-LLaVA能够接收并处理多种类型的输入,包括文本、图像和视频,集成视觉编码器和语言解码器,以理解和分析不同模态的数据。
- 基于Llama 3.1:该模型基于Llama 3.1,通过进一步的训练和调整,具备处理视觉数据的能力。
- 简化的代码结构:Mini-LLaVA的代码设计注重简洁性,便于理解和修改。
- 交错处理:模型支持交错处理图像、视频和文本,确保在保持输入顺序的同时,对不同模态的数据进行分析和响应。
- 预训练适配器:Mini-LLaVA借助预训练的适配器增强了Llama 3.1模型的视觉处理能力,使其能够更好地理解并生成与输入内容相关的输出。
Mini-LLaVA的项目地址
Mini-LLaVA的应用场景
- 教育与培训:作为教学工具,Mini-LLaVA帮助学生理解复杂的概念,通过图像、视频和文本的结合提供丰富的学习体验。
- 内容创作:辅助内容创作者生成图像描述、视频字幕或自动化生成文章和报告。
- 媒体与娱乐:在电影、游戏和视频制作中,生成剧本、角色对话或自动生成视频内容的描述。
- 智能助手:作为聊天机器人或虚拟助手的一部分,提供图像和视频理解能力,以更好地与用户互动。
- 社交媒体分析:分析社交媒体上的图像和视频内容,提取关键信息,帮助品牌和个人了解公众对内容的反应。
- 安全监控:在安全领域,对监控视频进行实时分析,识别异常行为或事件。
常见问题
- Mini-LLaVA是否支持多种输入类型?是的,Mini-LLaVA支持图像、文本和视频输入的处理。
- 我可以在什么样的硬件上运行Mini-LLaVA?该模型经过优化,可以在单个GPU上运行,非常适合资源有限的环境。
- 如何获取Mini-LLaVA?您可以通过访问其GitHub仓库下载Mini-LLaVA,链接为:https://github.com/fangyuan-ksgk/Mini-LLaVA
- Mini-LLaVA适合哪些应用场景?该模型适用于教育培训、内容创作、媒体娱乐、智能助手、社交媒体分析和安全监控等多个领域。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...

 粤公网安备 44011502001135号
粤公网安备 44011502001135号