MoE++是一种创新的混合专家(Mixture-of-Experts)框架,由昆仑万维2050研究院与北大袁粒团队共同开发。该架构通过引入零计算量专家(如零专家、复制专家和常数专家),有效降低了计算成本,并显著提升了模型性能。MoE++使得每个Token能够灵活地与不同数量的前馈网络专家进行交互,甚至可以跳过某些层,从而优化计算资源的分配。
MoE++是什么
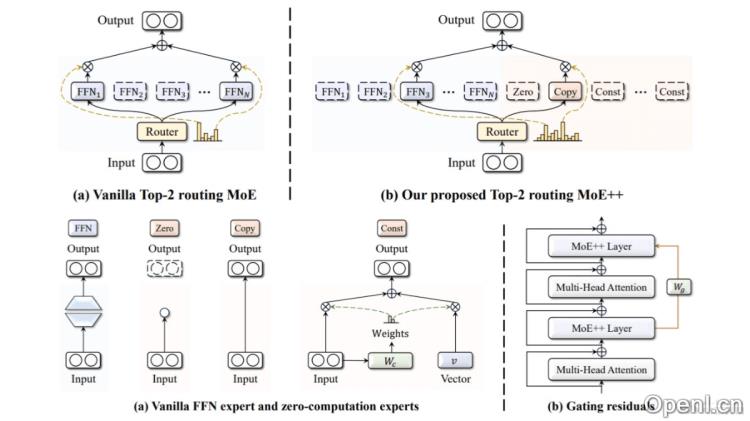
MoE++是一款前沿的混合专家架构,由昆仑万维2050研究院与北大袁粒团队联合研发。它通过引入零计算量专家(零专家、复制专家和常数专家),在降低计算负担的同时提升模型的整体性能。MoE++的设计允许每个Token动态选择不同数量的前馈网络专家进行处理,甚至可以跳过某些层,以优化计算资源的配置。通过门控残差机制,MoE++帮助Token在选择专家时参考前一层的路由路径,从而实现更加稳定的专家选择。实验结果显示,MoE++在同等模型规模下,性能优于传统的MoE模型,专家吞吐速度提升了1.1到2.1倍,且便于部署。
MoE++的主要功能
- 降低计算成本:引入零计算量专家,MoE++允许模型中的每个Token根据需要选择不同数量的前馈网络专家,甚至跳过不必要的层,从而减少计算资源的浪费。
- 提升模型性能:通过减少简单Token所需的FFN专家数量,MoE++能够释放更多资源用于处理复杂Token,从而提高整体模型性能。
- 优化资源分配:MoE++通过灵活的计算分配机制,确保将更多计算资源集中在需求更高的Token上,从而提升计算效率。
- 稳定路由:基于门控残差机制,MoE++在专家选择时参考前一层的路由路径,使得专家选择过程更加稳定。
- 易于部署:由于零计算量专家的参数量极小,MoE++能够在单一GPU上部署所有专家,避免了分布式FFN专家部署所带来的通信开销和负载不均问题。
MoE++的技术原理
- 零计算量专家:该架构引入了三种类型的零计算量专家,包括零专家(输出空向量)、复制专家(直接将输入作为输出)和常数专家(用可训练向量替代输入)。
- 动态专家选择:与传统MoE方法不同,MoE++允许每个Token根据其复杂程度动态选择不同数量的FFN专家进行处理。
- 门控残差:在专家选择过程中,MoE++引入门控残差机制,增强不同层之间的信息流动,使得Token在选择专家时能够参考前一层的路由路径。
- 异构专家结构:MoE++的专家结构是异构的,允许不同类型的专家(FFN专家和零计算量专家)在同一模型中协同工作,从而提高了模型的灵活性和适应性。
- 负载平衡:通过引入负载平衡损失和专家容量分配策略,MoE++确保在训练过程中专家之间的负载均衡,避免某些专家过载而其他专家闲置的问题。
MoE++的项目地址
- GitHub仓库:https://github.com/SkyworkAI/MoE-plus-plus
- HuggingFace模型库:https://huggingface.co/Chat-UniVi/MoE-Plus-Plus-7B
- arXiv技术论文:https://arxiv.org/pdf/2410.07348
MoE++的应用场景
- 自然语言处理(NLP)研究者:研究者可以利用MoE++构建更高效的大型语言模型,进行语言理解、文本生成、机器翻译和问答系统等领域的探索。
- 企业开发者:企业开发者可以借助MoE++开发高性能的NLP应用,如智能客服、内容推荐、自动摘要和情感分析等,以提升产品的智能化水平。
- 云计算和AI服务提供商:服务提供商可以集成MoE++架构,为客户提供更高效、成本更低的AI服务,特别是在处理大规模语言数据的场景中。
- 学术机构:学术机构能够通过MoE++进行各类NLP任务的教学和研究,帮助学生和研究人员理解先进的深度学习模型与算法。
常见问题
- MoE++与传统MoE的区别是什么? MoE++通过引入零计算量专家和动态专家选择机制,在降低计算成本的同时提升了模型性能,解决了传统MoE的局限性。
- 如何部署MoE++? 由于零计算量专家的参数量较小,MoE++可以在同一GPU上轻松部署,避免了复杂的分布式设置。
- MoE++适用于哪些应用? MoE++适用于各种需要高效处理语言数据的应用场景,包括自然语言处理、智能客服和AI服务等。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...

 粤公网安备 44011502001135号
粤公网安备 44011502001135号