MooER是摩尔线程推出的首个基于国产全功能GPU训练的开源音频理解大模型。具备中文和英文的语音识别能力,并且能够进行中译英的语音翻译,MooER在Covost2中译英测试集中取得了25.2的BLEU分数,接近工业级水平。摩尔线程的AI团队已经开源了推理代码和5000小时的训练模型,并计划进一步开源训练代码和8万小时训练模型,推动AI语音技术的发展。
MooER是什么
MooER是由摩尔线程开发的一款开源音频理解大模型,首创于基于国产全功能GPU训练的领域。它不仅支持中文和英文的语音转文本功能,还具备将中文语音翻译成英文文本的能力。MooER在多个测试中表现优异,显示出其接近工业级的效果。该模型的推理代码及部分训练模型已经开源,旨在促进AI语音技术的进一步研究与应用。
MooER的主要功能
- 语音识别:支持中文和英文的语音转文本,方便用户获取语音内容。
- 语音翻译:能够将中文语音翻译成英文文本,适合多语言交流。
- 高效训练:利用摩尔线程的智算平台,快速处理和训练大量数据。
- 开源模型:推理代码和部分训练模型已公开,便于开发者和研究者使用与研究。
MooER的技术原理
- 深度学习架构:MooER采用深度学习技术,特别是神经网络,来分析和理解语音信号。
- 端到端训练:模型直接从原始语音信号生成文本输出,简化了传统语音识别系统的多个模块。
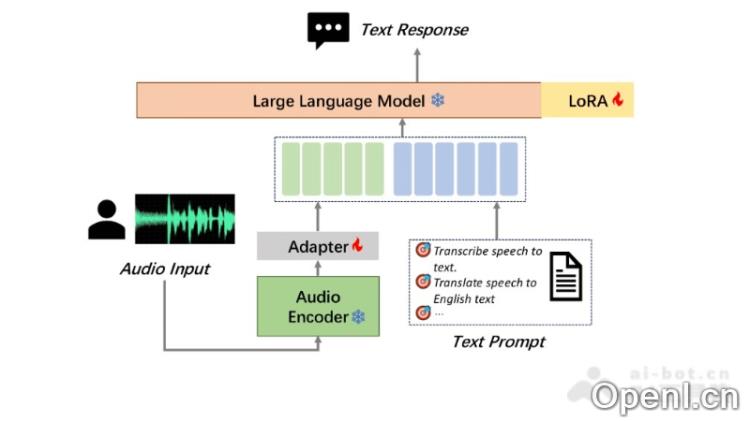
- Encoder-Adapter-Decoder结构:
- Encoder:将输入的语音信号转化为高级特征表示。
- Adapter:优化模型以适应特定任务,提高泛化能力。
- Decoder(Large Language Model,LLM):根据特征生成最终的文本输出。
- LoRA技术:采用低秩适应(LoRA)技术,这是一种高效的模型微调方法,通过更新少量参数提升训练效果。
- 伪标签训练:在训练中使用模型自身的预测作为伪标签,以增强学习能力。
- 多语言支持:MooER能够处理中文和英文的语音识别及中译英翻译,展现出其多语言处理能力。
MooER的项目地址
- GitHub仓库:https://github.com/MooreThreads/MooER
- arXiv技术论文:https://arxiv.org/pdf/2408.05101
- 在线体验地址:https://mooer-speech.mthreads.com:10077/
如何使用MooER
- 获取模型:访问Github仓库获取MooER模型的代码和预训练权重。
- 环境配置:确保计算环境中安装了所需的依赖库和工具,例如Python、深度学习框架(如TensorFlow或PyTorch)、音频处理库等。
- 数据准备:准备音频数据以及相应的文本转录,确保数据格式符合模型输入要求。
- 模型加载:将预训练的MooER模型加载到计算环境中。
- 数据处理:对音频数据进行预处理,如归一化和分帧,以符合模型的输入要求。
- 模型推理:使用MooER模型对处理后的音频数据进行推理,获取语音识别或翻译结果。
MooER的应用场景
- 实时语音转写:在会议、讲座和课堂等场合,MooER可实时将语音转换为文字,便于记录与回顾。
- 多语言翻译:支持中英文之间的语音翻译,适用于跨国会议及国际交流等场景。
- 智能客服:在客户服务领域,MooER可通过语音识别和翻译功能,提高响应效率和服务质量。
- 语音助手:可集成于智能手机、智能音箱等设备,提供语音交互服务。
- 教育辅助:在语言学习中,MooER可帮助学习者进行发音校正和语言翻译。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...

 粤公网安备 44011502001135号
粤公网安备 44011502001135号