Mora是由微软与理海大学的研究团队共同开发的多智能体(AI Agents)框架,旨在处理通用的视频生成任务。该框架的设计灵感源自于OpenAI的Sora视频生成模型,致力于通过多个视觉智能体的协同工作,产生高质量的视频内容。Mora将视频生成流程分解为多个子任务,并为每个子任务指派专门的智能体,从而实现多样化的视频生成功能。
Mora是什么
Mora是一个创新的多智能体框架,专门用于视频生成领域,由微软和理海大学的研究者们共同推出。其核心理念是利用多个视觉智能体的合作,生成高质量的视频内容。Mora通过将视频生成的复杂过程拆分为多个子任务,为每个任务分配特定的智能体,从而实现了多种视频生成能力。
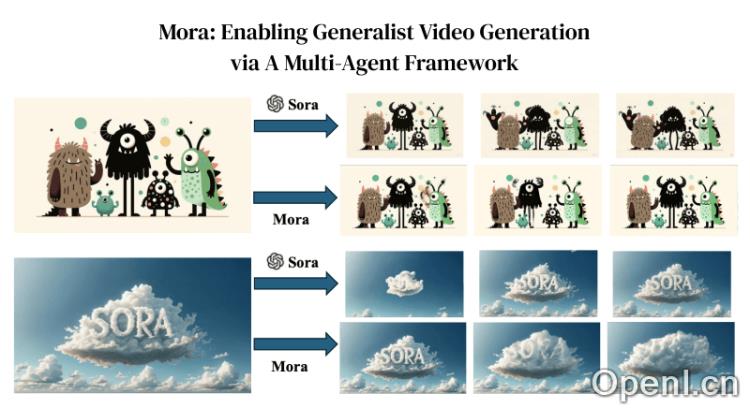
实验数据显示,Mora在生成高分辨率(1024×576)、时长为12秒的视频时表现优异,总共生成75帧。然而,在处理动态物体较多的场景时,Mora与Sora相比的性能表现存在明显差距。同时,尝试生成超过12秒的视频时,视频质量会显著下降。
Mora的主要功能
- 文本到视频生成:Mora能够根据用户提供的文本描述自动生成相应的视频内容,适用于从简单场景描述到复杂故事情节的创作。
- 图像到视频生成:Mora不仅支持从文本生成视频,还能结合用户提供的初始图像和文本提示,生成与之匹配的视频序列,增加内容的多样性和细节。
- 扩展生成视频:Mora可以对已有的视频内容进行扩展和编辑,增加新元素或延长视频时长。
- 视频编辑功能:Mora具有强大的编辑能力,能够根据用户的文本指令修改视频,如更改场景、调整对象特性或添加新元素。
- 视频连接:Mora能够将多个视频片段无缝连接,创造流畅的过渡效果,适合制作视频合集或剪辑。
- 模拟数字世界:Mora可以根据文本描述创建出具有数字世界风格的视频序列,如游戏场景或虚拟环境。
Mora的官网入口
- GitHub地址:https://github.com/lichao-sun/Mora(源码和模型待开源)
- arXiv研究论文:http://arxiv.org/abs/2403.13248
Mora的工作原理
Mora的工作机制基于一个多智能体架构,通过协同多个专业化的AI智能体来完成视频生成任务。每个智能体负责特定的子任务,这些任务共同构成了完整的视频生成流程。
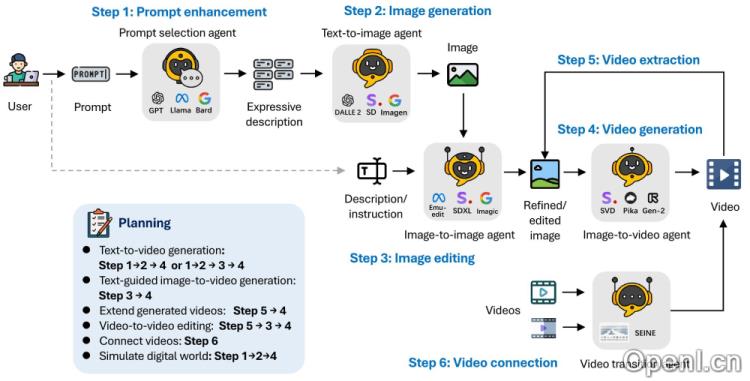
以下是Mora工作流程的详细步骤:
- 任务分解:Mora将复杂的视频生成任务拆分为多个子任务,每个子任务由一个专门的智能体负责。
- 智能体角色定义:Mora设定了五种基本角色的智能体:
- 提示选择与生成智能体:使用大型语言模型(如GPT-4或Llama)来优化和选择文本提示,以提高生成图像的相关性与质量。
- 文本到图像生成智能体:将文本提示转换为高质量的初始图像。
- 图像到图像生成智能体:根据文本指令对给定的源图像进行修改。
- 图像到视频生成智能体:将静态图像转化为动态视频序列。
- 视频连接智能体:基于两个输入视频创建平滑过渡的视频。
- 工作流程:Mora会根据任务需求,自动组织智能体按特定顺序执行子任务。例如,文本到视频生成的任务可能包括以下步骤:
- 首先,提示选择与生成智能体处理文本提示。
- 接着,文本到图像生成智能体根据优化后的文本提示生成初始图像。
- 然后,图像到视频生成智能体将初始图像转化为视频序列。
- 最后,如果需要,视频连接智能体可以将多个视频片段连接成一个连贯的视频。
- 多智能体协作:智能体通过预定义的接口和协议进行相互通信,确保整个视频生成过程的连贯性与一致性。
- 生成与评估:每个智能体完成其子任务后,会把结果传递给下一个智能体,直至完成整个视频生成过程。生成的视频将根据预定义的评估标准进行质量评估。
- 迭代与优化:Mora框架允许通过迭代与优化来提升视频生成的质量。智能体可以根据反馈调整其参数,以改善生成视频的质量与与文本提示的一致性。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...

 粤公网安备 44011502001135号
粤公网安备 44011502001135号