OLMo(开放语言模型)是由艾伦人工智能研究所(AI2)开发的一个完全开源的大型语言模型(LLM)框架,旨在通过开放研究推动学术界和研究人员在语言模型科学领域的合作。OLMo框架提供了丰富的资源,包括数据集、训练代码、模型权重和评估工具,使研究人员能够深入探讨和改进语言模型。
OLMo是什么?
OLMo(Open Language Model)是由艾伦人工智能研究所(AI2)推出的开源大型语言模型(LLM)框架。它的设计初衷是为了促进学术界和研究人员对语言模型科学的共同探索。OLMo框架整合了多种资源,包括数据、训练代码、模型权重以及评估工具,帮助研究人员深入理解和改进语言模型。

OLMo的官网入口
- 官方项目主页:https://allenai.org/olmo
- GitHub代码库:https://github.com/allenai/olmo
- Hugging Face地址:https://huggingface.co/allenai/OLMo-7B
- 研究论文:https://allenai.org/olmo/olmo-paper.pdf
OLMo的主要特点
- 海量预训练数据:OLMo基于AI2的Dolma数据集,这是一套包含3万亿个标记的大规模开放语料库,为模型提供了丰富的语言学习素材。
- 多样的模型版本:OLMo框架提供了四种不同规模的模型版本,每种模型至少经过2万亿个token的训练,满足不同研究需求的多样化选择。
- 详尽的训练和评估资源:除了模型权重,OLMo还提供完整的训练日志、训练指标及500多个检查点,帮助研究人员更好地理解模型的训练过程与性能表现。
- 开放性与透明性:OLMo的所有代码、权重和中间检查点均在Apache 2.0许可证下发布,研究人员可以自由使用、修改和分发这些资源,促进知识共享与创新。
OLMo的模型性能
根据OLMo的研究论文,OLMo-7B模型在零样本评估中与多个其他模型进行了比较,包括Falcon-7B、LLaMA-7B、MPT-7B、Pythia-6.9B、RPJ-INCITE-7B等。
以下是OLMo-7B在一些关键任务上的性能比较:
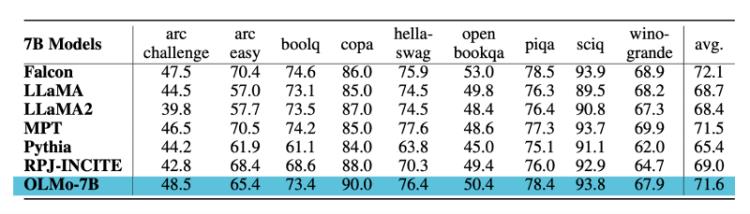
- 下游任务评估:在9个核心任务的零样本评估中,OLMo-7B在科学问题和因果推理两个任务上表现最佳,其余8个任务也均名列前茅,显示出其强大的竞争力。
- 困惑度评估:在Paloma评估框架下,OLMo-7B在多个数据源上的困惑度表现同样不俗,尤其是在与代码相关的数据源(如Dolma 100编程语言)上的表现显著优于其他模型。
- 额外任务评估:在额外的6个任务(headqa en、logiqa、mrpcw、qnli、wic、wnli)中,OLMo-7B在零样本评估中也表现出色,优于或接近其他模型。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...

 粤公网安备 44011502001135号
粤公网安备 44011502001135号