OmniCorpus是一个庞大的多模态数据集,涵盖了86亿张图像和16960亿个文本标记,支持中英双语,由上海人工智能实验室与多所知名高校及研究机构共同开发。其通过整合来自不同网站和视频平台的文本与视觉内容,显著提升了数据的多样性和质量,旨在推动多模态大语言模型的研究与应用。该数据集已在GitHub上公开,适用于多种机器学习任务。
OmniCorpus是什么
OmniCorpus是一个大规模的多模态数据集,包含86亿张图像和16960亿个文本标记,支持中英双语。它由上海人工智能实验室联合多所知名高校及研究机构共同构建。OmniCorpus通过整合来自不同网站和视频平台的文本与视觉内容,为研究人员提供了丰富的数据多样性。与现有数据集相比,OmniCorpus在规模和质量上都有显著提升,推动多模态大语言模型的研究和应用。数据集在GitHub上公开可用,适用于多种机器学习任务。
主要功能
- 多模态学习支持:结合图像与文本数据,适用于多模态机器学习模型的训练和研究,例如图像识别、视觉问答和图像描述。
- 大规模数据集:提供丰富的图像与文本数据,有助于训练和测试大型多模态模型,从而提高模型的泛化能力和性能。
- 数据多样性:涵盖了各种来源和类型的数据,包括不同语言和领域的内容,增强了数据集的多样性和应用范围。
- 灵活的数据格式:支持流式数据格式,能够适应多种数据结构,如纯文本语料库、图像-文本对和交错数据格式。
- 高质量数据:通过高效的数据引擎和人类反馈过滤机制,确保数据集的高质量,减少噪声和不相关内容。
技术优势
- 大规模数据集成:整合了86亿张图像和16960亿个文本标记,成为目前最大的多模态数据集之一。
- 高效的数据引擎:开发了高效的数据处理管道,能够快速处理和过滤大规模多模态数据,确保高质量输出。
- 丰富的数据多样性:数据来源于多种语言和不同类型的网站以及视频平台,提供了广泛的数据多样性。
- 灵活的数据格式:采用流式数据格式,能够灵活适应不同的数据结构和研究需求。
- 高质量的数据保证:通过细致的预处理步骤和人类反馈机制,提升了数据集的整体质量。
- 先进的过滤技术:使用BERT模型结合人工反馈来优化文本过滤,降低无关内容和噪声。
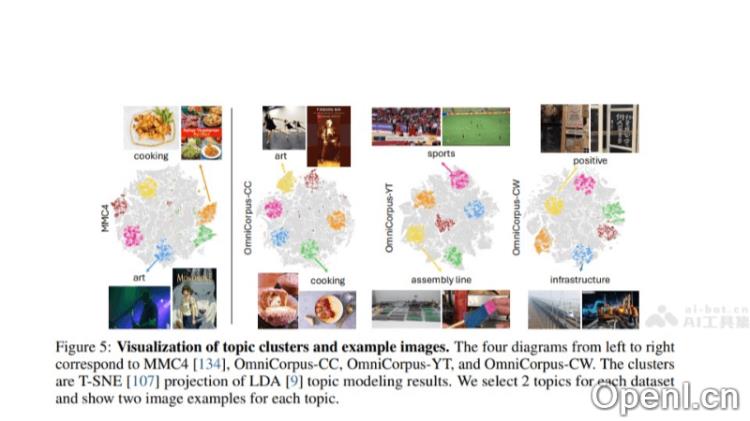
- 主题建模分析:基于LDA等技术进行主题建模,帮助研究人员理解数据集的内容分布和主题多样性。
项目地址
- GitHub仓库:https://github.com/OpenGVLab/OmniCorpus
- arXiv技术论文:https://arxiv.org/pdf/2406.08418
如何使用OmniCorpus
- 获取数据集:访问OmniCorpus的GitHub页面以下载数据集内容。
- 理解数据格式:熟悉数据集的组织结构和文件格式,包括图像文件、文本标记和元数据。
- 数据预处理:根据研究或应用需求,可能需要对数据进行进一步的预处理,如数据清洗、格式转换或数据分割。
- 模型训练:使用数据集训练多模态机器学习模型,如图像识别、视觉问答或图像描述模型。调整模型参数以适应数据集的特点。
- 模型评估:在数据集上评估模型性能,使用适当的评估指标,如准确率、召回率或F1分数。
应用场景
- 多模态学习:用于训练能够同时处理图像和文本的机器学习模型,提升模型对视觉和语言信息的理解能力。
- 视觉问答(VQA):构建能够理解图像内容并回答相关问题的系统,例如,对于给定的图片,回答有关图片内容的问题。
- 图像描述生成:开发自动为图片生成描述性文字的系统,这在社交媒体、图像搜索引擎和辅助技术中非常有用。
- 内容推荐系统:结合图像和文本数据,提供更精准的个性化内容推荐,例如电商产品推荐和新闻文章推荐等。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...

 粤公网安备 44011502001135号
粤公网安备 44011502001135号