Playground v3(PGv3)是由Playground Research推出的最新一代文本到图像生成模型,凭借深度融合的大型语言模型(LLM)技术,展现出超越人类设计师的出色能力。该模型参数量高达240亿,能够精确理解和生成复杂的图像内容,支持RGB颜色的精准控制,并具备多语言文本生成的能力。
Playground v3是什么
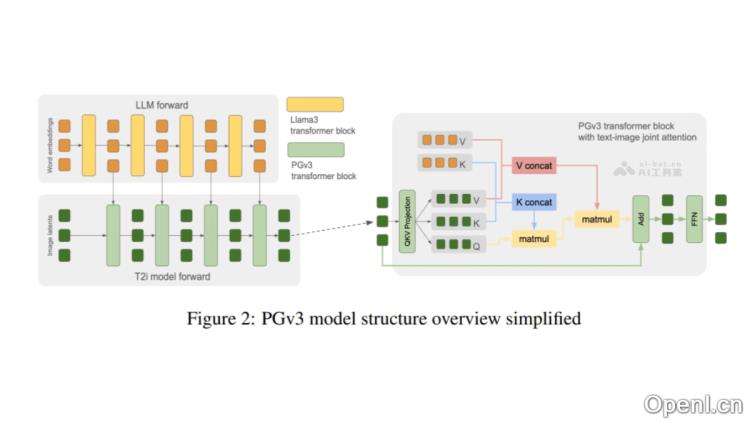
Playground v3(PGv3)是Playground Research推出的先进文本到图像生成模型,基于深度融合的大型语言模型(LLM)技术,旨在图形设计领域超越传统设计师的表现。PGv3具备240亿的参数量,能够深入理解并生成复杂的图像内容,同时支持精确的RGB颜色调整和多语言文本生成。其模型架构采用潜扩散模型(LDM),结合变分自编码器(VAE)和经验扩散模型(EDM)进行训练,使用DiT风格的模型结构,使每个Transformer模块与语言模型中的对应模块一致,从而提升对提示的理解与遵循能力。PGv3在文本提示的解析、复杂推理和文本渲染的准确性方面表现优异,特别是在表情包、海报和标志设计等应用中,展现出卓越的设计潜力。此外,PGv3引入了新的评估基准CapsBench,推动了图像描述评估方法的进步。
Playground v3的主要功能
- 文本到图像生成:根据用户输入的文本描述生成相应的图像。
- 图形设计能力:在表情包、海报和标志等设计任务中展现出超越人类设计师的能力。
- 精准RGB颜色控制:支持对特定颜色要求的图像进行精确控制。
- 多语言支持:能够理解和生成多种语言,满足全球用户的需求。
Playground v3的技术原理
- 大型语言模型集成:PGv3集成了如Llama3-8B等大型语言模型,增强了文本理解和生成的能力。
- 深度融合架构:基于全新的深度融合架构,利用仅解码器的大型语言模型知识进行文本到图像生成。
- 变分自编码器(VAE):使用VAE提升图像质量,增强细节合成的能力。
- 高参数量:240亿的参数量使模型能够捕捉和生成更为复杂和细致的图像特征。
- DiT风格的模型结构:基于与语言模型中相同的Transformer块结构,增强了提示的理解和遵循能力。
- U-Net跳跃连接:在Transformer块之间引入U-Net跳跃连接,增强特征传递能力。
Playground v3的项目地址
- HuggingFace模型库:https://huggingface.co/datasets/playgroundai/CapsBench
- arXiv技术论文:https://arxiv.org/pdf/2409.10695
Playground v3的应用场景
- 图形设计:用于创作海报、标志、宣传册、社交媒体图像及其他营销材料。
- 内容创作:帮助内容创作者快速生成文章、博客或社交媒体帖子的个性化图像。
- 游戏开发:在游戏设计中,用于生成概念艺术、环境背景或角色设计。
- 电影和娱乐:生成电影海报、动画背景或视觉效果的概念图。
- 广告行业:用于设计广告牌、横幅广告及其他广告材料。
- 教育和研究:生成教学材料中的插图,帮助研究人员可视化复杂概念。
- 艺术创作:艺术家利用PGv3探索新的艺术风格,创作数字艺术作品。
常见问题
1. Playground v3支持哪些语言?
PGv3支持多种语言的文本生成,能满足不同语言用户的需求。
2. Playground v3适合哪些行业使用?
PGv3广泛应用于图形设计、内容创作、游戏开发、广告、教育等多个领域。
3. 如何访问Playground v3?
用户可以通过HuggingFace模型库和arXiv技术论文链接获取PGv3的详细信息和访问权限。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...

 粤公网安备 44011502001135号
粤公网安备 44011502001135号