PUMA是一款尖端的多模态大型语言模型(MLLM),旨在通过整合多种视觉特征,提升视觉生成与理解的任务能力。它可以实现从文本生成图像、进行精细图像编辑,以及执行其他多样的视觉任务,满足不同层次的细节需求。PUMA项目由来自CUHK MMLab、HKU MMLab、SenseTime、上海人工智能实验室和清华大学的研究者合作开发,持续更新至2024年10月,推动了AI视觉语言模型的前沿,提供了灵活而强大的多模态AI解决方案。
PUMA是什么
PUMA是一个先进的多模态大型语言模型(MLLM),旨在整合多种粒度的视觉特征,以增强视觉生成和理解的能力。PUMA可以处理多样的任务,包括文本到图像的生成、精细的图像编辑,以及其他视觉相关的任务,能够适应不同细节层次的需求。通过多模态的预训练和微调技术,PUMA在文本到图像生成、图像编辑、条件图像生成和视觉语言理解等多种应用中展示出了卓越的性能。该项目的持续发展旨在推动AI视觉语言模型的边界,为多模态AI的未来探索提供创新的解决方案。
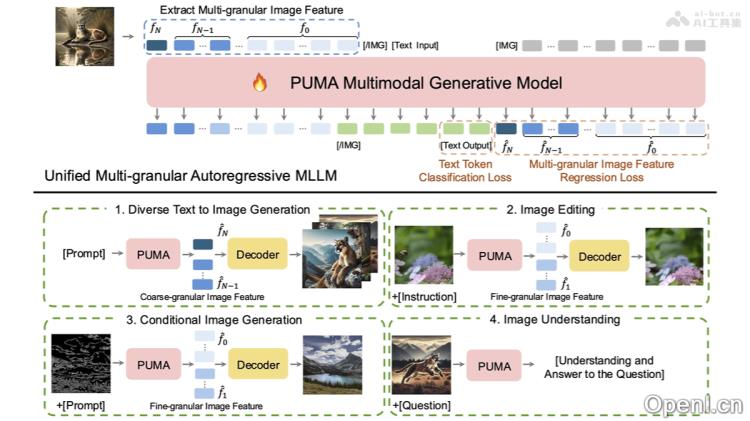
PUMA的主要功能
- 多样化的文本到图像生成:PUMA能够根据文本提示生成富有创意和高质量的图像,借助粗粒度的视觉特征提升其创造性和一致性。
- 精准图像编辑:PUMA利用细粒度的图像特征实现精准的图像编辑,包括对象的添加或移除、风格调整等,确保原始图像的保真度保持不变。
- 条件图像生成:PUMA擅长根据特定条件生成图像,例如从草图生成完整图像、进行图像修复或着色,确保生成结果既准确又符合上下文。
- 多粒度视觉解码:PUMA通过五种不同粒度的图像表示及对应的解码器,实现从精确图像重建到语义引导生成的广泛视觉解码能力。
PUMA的技术原理
- 多粒度图像编码:PUMA采用图像编码器对输入图像进行处理,提取从细粒度到粗粒度的多层次视觉特征,为生成多样化和可控的图像打下基础。
- 自回归MLLM:PUMA的自回归多模态大型语言模型(MLLM)能够处理和生成多尺度的文本与视觉tokens,适应不同任务的需求。
- 扩散式解码器:PUMA运用一系列与不同特征粒度对应的扩散式解码器,进行视觉解码,支持高可控性和高多样性的输出。
- 两阶段训练策略:PUMA通过多模态预训练和特定任务的指令微调,优化模型在多任务处理中的表现,使其在多样的视觉任务中都能出色完成。
PUMA的项目地址
- 项目官网:rongyaofang.github.io/puma
- GitHub仓库:https://github.com/rongyaofang/PUMA
- arXiv技术论文:https://arxiv.org/pdf/2410.13861
PUMA的应用场景
- 艺术创作与设计:PUMA能根据文本描述生成多样化的图像,为艺术家和设计师提供灵感或直接创作具有特定风格和主题的艺术作品。
- 媒体与娱乐:在电影、游戏和动画制作中,PUMA能够生成背景、场景或概念艺术,加速创意实现的过程。
- 广告与营销:PUMA能够根据营销文案快速生成吸引人的广告图像,帮助品牌以更低的成本和更快的速度制作视觉内容。
- 教育与培训:PUMA能够生成教学材料中的插图和示例图像,使教育内容更加生动与互动。
- 电子商务:在线零售商可以使用PUMA生成产品的视觉展示,例如,根据描述生成产品图片或改变产品颜色和样式。
常见问题
- PUMA如何生成图像?:PUMA通过分析输入的文本提示,结合其强大的图像生成能力,生成符合描述的高质量图像。
- PUMA的图像编辑功能有哪些?:PUMA允许用户进行对象添加或移除、风格调整等多种编辑操作,确保原始图像的质量不受影响。
- PUMA适合哪些行业使用?:PUMA广泛适用于艺术创作、媒体娱乐、广告营销、教育培训和电子商务等多个行业。
- PUMA的技术支持在哪?:用户可以通过PUMA的官方网站和GitHub仓库获取支持和相关文档资料。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...

 粤公网安备 44011502001135号
粤公网安备 44011502001135号