Qwen2-Audio是一款创新的开源AI语音模型,由阿里通义千问团队开发。它支持直接的语音输入和多种语言的文本输出,具备语音聊天和音频分析功能,能够处理超过8种语言,表现出色,已成功集成至Hugging Face的transformers库,便于开发者使用。
Qwen2-Audio是什么
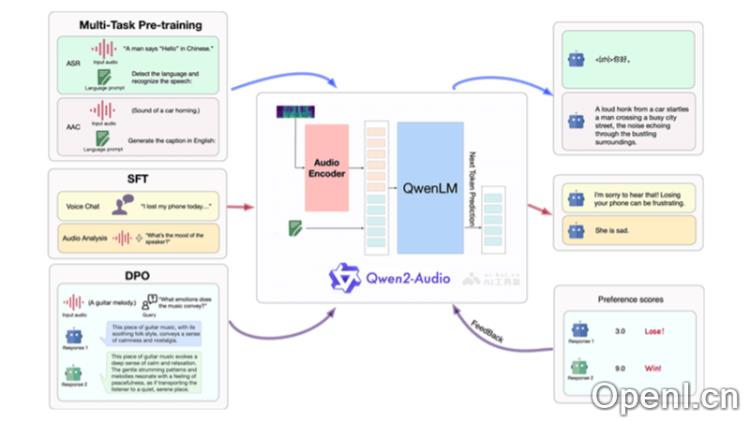
Qwen2-Audio是阿里通义千问团队最新发布的开源AI语音模型,能够支持直接的语音输入和多语言文本输出。此模型具备语音聊天和音频分析功能,支持多达8种语言。Qwen2-Audio在多个基准数据集上展现出了优异的性能,并已集成到Hugging Face的transformers库中,方便开发者进行调用与使用。此外,用户还可以通过ms-swift框架对模型进行微调,以满足特定的应用需求。

Qwen2-Audio的主要功能
- 语音对话:用户可以通过语音与模型进行无缝交流,无需借助ASR(自动语音识别)技术。
- 音频分析:能够根据文本指令分析音频内容,识别语音、声音和音乐等元素。
- 多语言支持:涵盖中文、英语、粤语、法语等多种语言和方言。
- 卓越性能:在多个基准数据集上表现优于以往的模型,成绩斐然。
- 简单集成:代码已集成到Hugging Face的transformers库,方便开发者使用和进行推理。
- 可微调性:支持通过ms-swift框架进行模型微调,以适应不同的应用需求。
Qwen2-Audio的技术原理
- 多模态输入处理:该模型能够接收并处理音频和文本两种输入方式,音频输入通过特征提取器转化为模型可理解的数值特征。
- 预训练与微调:在大量的多模态数据上进行预训练,以学习语言与音频的联合表示,并在特定任务上进行微调,提升模型在特定场景下的表现。
- 注意力机制:模型利用注意力机制增强音频与文本之间的关联性,在生成文本时充分考虑音频内容的信息。
- 条件文本生成:Qwen2-Audio支持根据给定的音频和文本条件生成相应的文本响应。
- 编码器-解码器架构:该模型采用编码器-解码器架构,编码器负责处理输入的音频和文本,而解码器生成输出文本。
- Transformer架构:作为transformers库的一部分,Qwen2-Audio利用Transformer架构,这是处理序列数据的深度学习模型,广泛应用于自然语言处理任务。
- 优化算法:在训练期间,使用优化算法(如Adam)调整模型参数,以最小化损失函数,从而提高预测的准确性。
Qwen2-Audio的项目地址
- 体验Demo:https://huggingface.co/spaces/Qwen/Qwen2-Audio-Instruct-Demo
- GitHub仓库:https://github.com/QwenLM/Qwen2-Audio
- arXiv技术论文:https://arxiv.org/pdf/2407.10759
Qwen2-Audio的应用场景
- 智能助手:作为虚拟助手,能够通过语音与用户进行互动,回答问题或提供帮助。
- 语言翻译:实现实时语音翻译,促进跨语言的交流。
- 客服中心:自动化客户服务,处理咨询并解决问题。
- 音频内容分析:分析音频数据,用于情感分析、关键词提取或语音识别等任务。
常见问题
- Qwen2-Audio支持哪些语言? 该模型支持超过8种语言,包括中文、英语、法语等。
- 如何使用Qwen2-Audio进行开发? 您可以通过Hugging Face的transformers库轻松集成该模型,并使用提供的API进行开发。
- 模型是否可以微调? 是的,Qwen2-Audio支持通过ms-swift框架进行微调,以适应特定的应用场景。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...

 粤公网安备 44011502001135号
粤公网安备 44011502001135号