Reverb ASR是Rev公司推出的一款开源自动语音识别与说话人分离模型,凭借20万小时的人工转录英语数据进行深度训练,展现出卓越的长语音识别能力。该模型特别适用于处理播客、财报电话会议等场景,用户可以灵活控制输出文本的逐字程度,从完全逐字到非逐字的不同风格,满足精确转录和可读性的双重需求。
Reverb ASR是什么
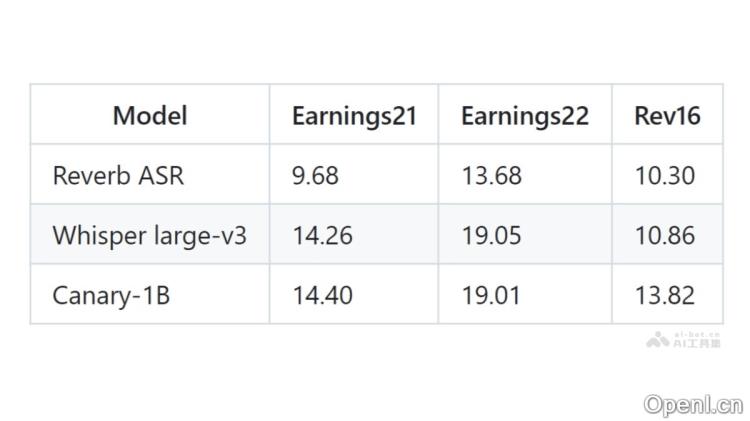
Reverb ASR是Rev公司开发的开源自动语音识别和说话人分离模型,经过20万小时的人工转录英语数据训练而成。其在长语音识别方面表现优异,尤其适合处理如播客和财报电话会议等场合。用户可以根据需求调节输出文本的逐字程度,从完全逐字到非逐字,适应不同的使用场景。Reverb ASR支持多种解码模式,包括注意力解码和CTC前缀束搜索,以适应不同的识别任务。在长语音处理领域,Reverb ASR的表现超越了许多现有的开源模型,例如OpenAI的Whisper和NVIDIA的Canary-1B。
Reverb ASR的主要功能
- 高精度语音识别:高效、准确地将英语语音转换为文本。
- 逐字稿控制:用户可以根据需求调整输出的逐字稿程度,适应不同场合。
- 多种解码模式:支持多种解码模式,包括注意力解码、CTC贪婪搜索、CTC前缀束搜索等。
- 长篇幅语音处理:擅长处理长时间语音输入,如播客和会议记录。
- 说话人分离:能够有效区分和识别不同的说话人。
Reverb ASR的技术原理
- 数据集:模型训练所用的数据集涵盖20万小时的英语语音,由人类专家转录,涵盖多种领域、口音和录音条件。
- 联合CTC/注意力架构:基于连接时序分类(CTC)与注意力机制相结合的架构,支持模型在语音识别时同时考虑语音的序列特性和上下文信息。
- 编码器-解码器结构:模型采用18层卷积编码器与6层双向注意力解码器,帮助捕捉长期依赖关系与短时语音特征。
- 语言特定层:在编码器和解码器的第一层和最后一层引入语言特定层,以便更好地控制输出的逐字程度。
- 模型量化:提供Int8量化版本的ASR模型,提升推断速度,减少内存占用,适应速度和内存敏感的应用需求。
- 多种解码模式:支持多样化的解码模式,包括贪婪CTC解码、CTC前缀束搜索、注意力解码和联合CTC/注意力解码。
Reverb ASR的项目地址
- GitHub仓库:https://github.com/revdotcom/reverb/tree/main/asr
- HuggingFace在线体验Demo:https://huggingface.co/spaces/Revai/reverb-asr-demo
- arXiv技术论文:https://arxiv.org/pdf/2410.03930v1
Reverb ASR的应用场景
- 播客制作:自动转录播客内容,便于后期编辑和内容管理。
- 会议记录:实时生成商务会议或学术研讨会的会议记录。
- 法庭记录:提供法庭审理过程的准确记录,确保法律程序的严谨性。
- 语音内容创作:帮助内容创作者将语音转化为文本,提升工作效率。
- 语言学习:辅助语言学习者进行发音和听力练习,提供即时反馈。
- 媒体监控:监控广播、电视或其他媒体的语音内容,便于进行新闻分析或舆情监控。
- 客户服务:在呼叫中心自动记录和分析客户对话,提升服务质量。
常见问题
- Reverb ASR支持哪些语言?:目前主要支持英语语音识别。
- 如何使用Reverb ASR?:用户可以通过GitHub仓库下载模型并按照说明进行部署和使用。
- 在什么场景下使用Reverb ASR效果最佳?:在长时间的语音输入场景,如播客和会议记录中,Reverb ASR能发挥其最佳性能。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...

 粤公网安备 44011502001135号
粤公网安备 44011502001135号