SafeEar是一款由浙江大学和清华大学联合研发的人工智能音频伪造检测框架。该框架旨在保护用户隐私的同时,精确地识别音频伪造。通过采用基于神经音频编解码器的解耦模型,SafeEar能够有效分离语音中的声学信息与语义信息,从而利用声学特征进行伪造检测,确保隐私不被泄露。
SafeEar是什么
SafeEar是一种高效的AI音频伪造检测工具,旨在在不暴露用户的语音内容的前提下,精准识别音频伪造。它利用先进的神经音频编解码器技术,将音频的声学信息与语义信息进行分离,能够在多个标准数据集上实现低至2.02%的等错误率(EER),有效应对内容恢复攻击。此外,SafeEar还支持多种语言,搭建了包含150万条多语种音频数据的CVoiceFake数据集,为语音伪造检测的研究提供了重要资源。
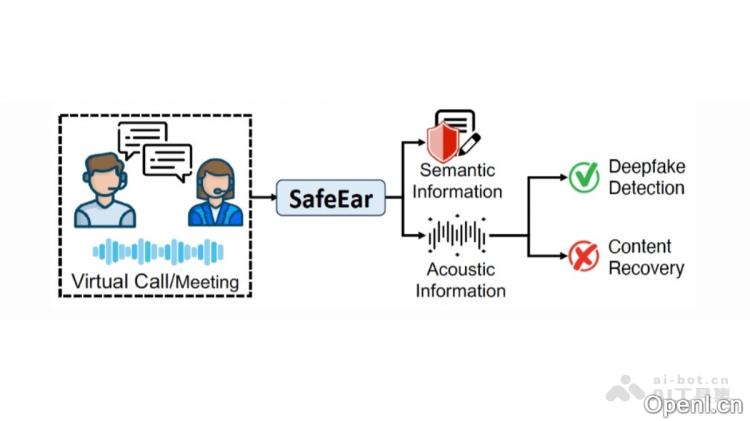
SafeEar的主要功能
- 隐私保护的伪造检测:SafeEar通过分离语音的语义和声学信息,仅依赖声学特征进行深度伪造音频的检测,确保在检测过程中不泄露语音内容。
- 多语言兼容性:该系统能够处理多种语言的音频数据,支持包括英语、中文、德语、法语和意大利语等多种语言。
- 高效的检测能力:经过多项公开基准测试,SafeEar的等错误率(EER)低至2.02%,表明其在伪造音频检测方面的高效性。
- 抗内容恢复技术:结合真实场景的编解码器增强技术,SafeEar能够抵御多种音频伪造方法,在对抗性攻击下仍保持高准确率。
- 真实环境模拟增强:通过模拟不同通信环境中的音频信道,SafeEar提升了模型在各种场景下的适应能力。
- 开源资源共享:SafeEar为研究社区提供论文、代码及数据集的开放访问,促进进一步的研究与应用开发。
- CVoiceFake数据集构建:SafeEar构建的CVoiceFake数据集包含150万条多语种音频样本,为语音伪造检测提供了标准化的测试基准。
SafeEar的技术原理
- 语义与声学信息的分离:SafeEar运用神经音频编解码器模型,将音频中的语义信息(如语言内容)与声学信息(如音色、语调和节奏)有效分离,这一机制确保了在伪造音频检测时不会泄露具体内容,从而保护用户隐私。
- 声学特征分析:该系统专注于音频的声学特征分析,而非语义内容,利用音调、音色和节奏等声学特征进行有效识别。
- 多语言处理能力:SafeEar可以处理多种语言的音频数据,采用去语义化的方式,确保在分析中不暴露具体语义。
- 抗内容恢复技术:该技术结合了现实场景的编解码器增强,能够抵御多种音频伪造方法,确保高准确率。
- Transformer分类器:SafeEar采用基于声学输入的Transformer分类器,显示出在伪造检测中的潜力,提升了检测的精准度与效率。
SafeEar的项目地址
- 项目主页:safeearweb.github.io/Project/
- Github仓库:https://github.com/LetterLiGo/SafeEar
- 技术论文:https://safeearweb.github.io/Project/files/SafeEar_CCS2024.pdf
SafeEar的应用场景
- 社交媒体和公共论坛:在这些平台上,音频内容的伪造可能会导致误导或欺骗,SafeEar能够检测并标记这些伪造音频。
- 法律与司法系统:音频证据的真实性在法律程序中至关重要,SafeEar可以帮助确认录音的真实性。
- 金融行业:在客户服务和交易验证中,语音识别系统可能面临伪造音频的威胁,SafeEar可增强交易的安全性。
- 政府及安全机构:在国家安全和公共安全领域,检测伪造音频信息至关重要,SafeEar能够识别潜在威胁和虚假信息。
- 在线教育:在在线课程和考试中,SafeEar能够确保音频材料的真实性,防止学术不端行为。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...

 粤公网安备 44011502001135号
粤公网安备 44011502001135号