ScreenAI:智能屏幕信息处理的前沿工具
ScreenAI是什么
ScreenAI是谷歌研究团队开发的一款先进的可读屏AI视觉语言模型,旨在深度理解和解析用户界面(UI)及信息图表。该模型基于PaLI架构,结合了视觉与语言处理的能力,并借鉴了Pix2Struct的灵活拼贴策略,从而能够理解和生成与屏幕UI元素相关的文本内容,包括问题回答、UI导航指令及内容摘要。
- arXiv研究论文:https://arxiv.org/abs/2402.04615
- GitHub PyTorch实现:https://github.com/kyegomez/ScreenAI
ScreenAI的主要功能

- 屏幕信息解析:ScreenAI具备识别和理解UI元素及信息图表内容的能力,包括元素类型、位置及其相互关系。
- 问题回答(QA):该模型能够理解所获取的视觉信息,并对与UI和信息图表内容相关的问题进行回答。
- UI导航:ScreenAI能够解析导航指令(例如“返回”),并识别适当的UI元素进行交互,以有效理解用户意图并准确导航界面。
- 内容概括:模型能够简明扼要地总结屏幕内容,提炼屏幕信息的核心要点。
- 适应多种屏幕格式:ScreenAI能够处理不同分辨率和宽高比的屏幕截图,适应移动设备与台式机等多种设备的屏幕格式。
ScreenAI的技术原理
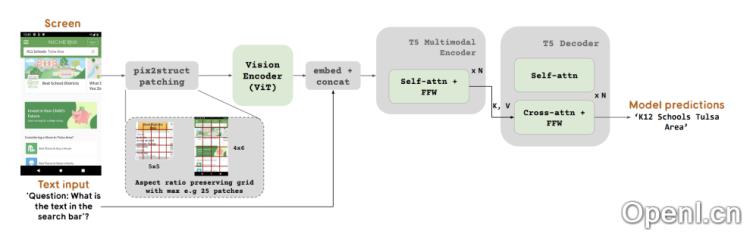
- 多模态编码器:受PaLI架构启发,ScreenAI采用多模态编码器块,包含视觉编码器和语言编码器。视觉编码器基于Vision Transformer (ViT) 架构,将输入的屏幕截图转化为一系列图像嵌入,而语言编码器则处理与这些屏幕截图相关的文本信息,如UI元素的标签和描述。
- 图像与文本融合:在多模态编码器中,图像嵌入与文本嵌入相结合,使模型能够同时理解视觉内容与相关语言信息,从而处理复杂的屏幕交互任务。
- 自回归解码器:编码器的输出传递给一个自回归解码器T5,负责生成文本输出,能够基于输入的图像和文本嵌入产生自然语言响应。
- 自动数据生成:为训练ScreenAI,研究人员利用自动数据生成技术,采用PaLM 2-S语言模型生成合成训练数据,包括屏幕模式及相应的问题-答案对。这一方法提升了数据的多样性和复杂性,减少了对手动标注的需求。
- 图像分割策略:ScreenAI利用Pix2Struct技术处理不同分辨率和宽高比的屏幕截图,允许模型根据输入图像的形状和预定义的最大块数生成任意网格形状的图像块,从而适应各种屏幕格式。
- 模型配置与训练:ScreenAI提供670M、2B和5B参数的多个模型版本。这些模型在预训练阶段采用不同的起点,例如从PaLI-3的多模态预训练检查点开始。预训练任务与微调任务的结合,使模型能够在多种任务上进行训练和优化。
应用场景
ScreenAI可以广泛应用于多种场景,包括但不限于:
- 用户界面设计反馈,提升设计的易用性和可访问性。
- 智能助手,通过理解界面内容来提供更为精准的用户支持。
- 教育领域,辅助学生理解复杂的信息图表和界面布局。
- 数据分析,快速提炼和总结图表数据的核心信息。
常见问题
1. ScreenAI支持哪些屏幕格式?
ScreenAI支持多种屏幕格式,包括不同分辨率和宽高比的设备截图,能够适应移动设备和台式机。
2. 如何获取ScreenAI的技术文档?
可以通过访问arXiv和GitHub链接获取相关的研究论文和代码实现。
3. ScreenAI适合用于哪些行业?
ScreenAI适用于多个行业,包括教育、用户体验设计、数据分析等领域。
4. ScreenAI的训练数据是如何生成的?
研究人员使用自动数据生成技术,结合PaLM 2-S语言模型来生成合成训练数据,提升数据多样性。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...

 粤公网安备 44011502001135号
粤公网安备 44011502001135号