Seed-TTS是一款由字节跳动研发的高级文本到语音(TTS)模型,能够生成与自然人声极为相似的高品质语音。其独特的上下文学习能力和情感控制功能,使其适用于多种应用场景,如有声读物、视频配音等。
Seed-TTS是什么
Seed-TTS是字节跳动推出的一系列先进文本到语音(Text to Speech,TTS)模型,能够生成与人类语音非常接近的高质量发声。该系统不仅具备强大的上下文理解能力,还能精细调控语音的情感、语调和说话风格,适合于有声书籍、视频配音等多种应用。同时,Seed-TTS还具备零样本学习能力,即使在缺乏训练数据的情况下,也能生成高质量的语音,并支持内容编辑与多语种翻译。

Seed-TTS的主要功能
- 高质量语音生成:Seed-TTS采用了先进的自回归模型和声学声码器技术,生成的语音接近自然人声,经过大量数据训练,学习了丰富的语音特征和语言模式,确保输出清晰、流畅且自然。
- 上下文学习能力:该模型能够根据输入文本的上下文生成相应的语音,确保在连续对话或独立句子中,语音的连贯性和一致性。
- 情感调控:用户可以根据文本内容或情感标签控制语音的情感色彩,如愤怒、快乐、悲伤等,模型会相应调整语音的音调和节奏。
- 语音属性控制:除了情感,Seed-TTS还支持对语调、节奏和说话风格的调节,以满足不同场景的需求。
- 零样本学习能力:即使没有特定说话者的训练数据,Seed-TTS也能基于其广泛的训练经验生成优质语音,快速适应新说话者或语言。
- 语音编辑功能:支持对生成语音的内容和速度进行编辑,用户可根据需求修改特定部分或调整语速。
- 多语言支持:模型能够处理多种语言的文本输入,生成相应语言的语音,适用于全球化应用。
- 语音属性分解:通过自我蒸馏技术,Seed-TTS能够将语音的音色与其他属性分离,提供更高的灵活性和控制力。
Seed-TTS的官网入口
- 官方项目入口:https://bytedancespeech.github.io/seedtts_tech_report/
- arXiv技术论文:https://arxiv.org/pdf/2406.02430
Seed-TTS的工作原理
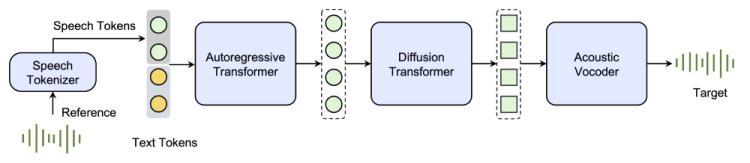
- 语音标记化:Seed-TTS首先用语音分词器将输入的语音信号转化为一系列离散的语音标记,这些标记是语音合成的基础。
- 条件文本与语音处理:自回归语言模型根据输入文本和语音标记生成目标语音的标记序列,确保生成的语音在语义和语法上与输入文本匹配。
- 语音表示生成:生成的语音标记序列被传入扩散变换器模型,将离散标记转化为连续语音表示,逐步细化生成自然的语音波形。
- 声学声码器:连续的语音表示接着送入声学声码器,转换为可听的高质量语音,声码器利用深度学习技术模拟人类声道的发声过程。
- 训练与微调:Seed-TTS模型在大量数据上进行预训练,之后可以通过微调适应特定说话者或语音风格,提升语音的自然度和表现力。
- 自我蒸馏与强化学习:Seed-TTS使用自我蒸馏技术实现语音属性的分解,并应用强化学习增强模型的鲁棒性和可控性。
- 端到端处理:非自回归变体Seed-TTSDiT采用完全基于扩散的架构,直接实现从文本到语音的端到端处理。
如何使用Seed-TTS
目前Seed-TTS仅提供技术论文和官方演示,尚未开放使用地址,感兴趣的用户可以访问官网查看相关演示。
Seed-TTS的应用场景
- 虚拟助手:为虚拟助手提供自然流畅的语音交互能力,提升用户体验。
- 有声读物与音频书籍:将电子书籍转换为高质量的有声读物,供用户聆听。
- 视频配音:在视频内容中使用Seed-TTS进行配音,尤其适合需要特定情感表达的场景。
- 客户服务自动化:在客户服务领域,Seed-TTS支持自动语音回复,处理常见咨询与信息查询。
- 电影与游戏配音:可用于电影制作和视频游戏开发中的角色配音,提供多样化的声音选择。
- 新闻与播客制作:快速将文本新闻或播客稿件转换为语音,制作音频内容。
- 辅助残障人士:为有语言障碍的人士提供语音合成服务,帮助他们更好地进行沟通。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...

 粤公网安备 44011502001135号
粤公网安备 44011502001135号