Snap Video是一款由Snap公司研发的先进AI视频生成模型,旨在通过用户输入的文本描述合成高质量的视频内容。该模型在生成视频时特别注重时间连续性和运动质量,有效地解决了文本到视频生成中存在的挑战。与其他同类模型如Pika和Runway Gen-2相比,Snap Video展现了更优越的性能。
Snap Video是什么
Snap Video是Snap(知名社交媒体Snapchat的母公司)研究团队推出的一款AI视频生成模型。用户只需输入一段描述性文本,Snap Video便能根据该文本生成相应的视频内容。考虑到视频内容的复杂性和冗余性,Snap Video专注于生成高质量、时间上连贯且运动保真的视频,力求超越现有的文本到视频技术。
Snap Video的官网入口
Snap Video的主要功能
- 专为视频生成设计:Snap Video是一个视频优先模型,特别优化了视频的时间连续性和运动表现,区别于其他通常从图像生成扩展而来的模型。
- 增强的EDM框架:该模型扩展了EDM框架,提升了处理视频数据时的质量,能够更好地应对空间和时间的冗余性。
- 高效的Transformer架构:Snap Video基于Transformer的FIT架构,有效处理序列数据,特别是在生成高分辨率视频时表现优越。
- 迅速的训练与推理:与传统的U-Net等架构相比,Snap Video在训练和推理速度上更具优势,能够高效地生成视频。
- 生成高分辨率视频:Snap Video能够合成高分辨率视频内容,克服了以往文本到视频生成模型在细节和运动复杂性上的挑战。
- 空间-时间联合建模:通过同时考虑空间和时间维度,Snap Video能够生成更具动态性和时间一致性的视频。
Snap Video的技术架构
- 扩展的EDM框架:Snap Video对EDM框架进行了适应性扩展,以支持高分辨率视频的生成,确保在保持信噪比的同时维持性能。
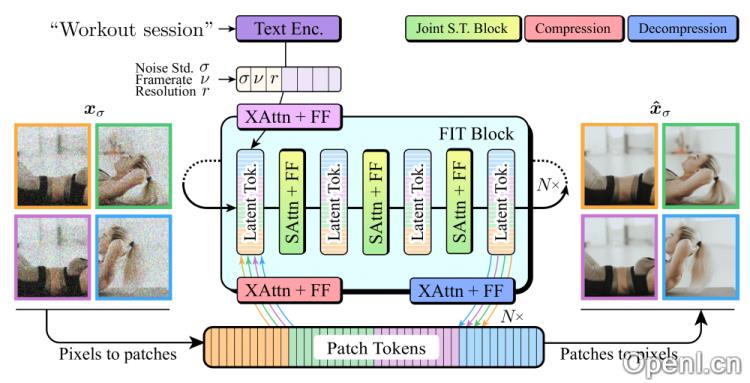
- 变换器架构:采用基于变换器(Transformer)的架构,Snap Video利用自注意力和跨注意力机制捕捉视频帧中的全局依赖关系,生成连贯的运动视频。
- FIT架构:使用FIT(Far-reaching Interleaved Transformers)架构,专为高分辨率图像和视频合成设计,使得Snap Video能够有效处理高分辨率视频数据。

- 空间-时间联合建模:在视频生成过程中,Snap Video同时关注空间和时间维度,提升了视频的动态变化和运动质量。
- 两阶段级联模型:Snap Video采用两阶段的级联生成策略,先生成低分辨率视频,再通过上采样生成高分辨率视频,确保了性能和质量。
- 训练与推理过程:在训练中,Snap Video使用了LAMB优化器并采用余弦学习率调度;推理过程中,模型通过确定性采样器生成视频样本,并应用分类器自由引导(Classifier-Free Guidance)提高文本与视频的对齐性。
- 条件信息整合:在生成过程中,Snap Video利用文本描述、噪声水平、帧率和分辨率等条件信息,通过额外读取操作控制生成流程。
应用场景
Snap Video可以广泛应用于短视频制作、广告创意、教育视频生成以及社交媒体内容创作等多个领域。无论是营销推广还是个人创作,Snap Video都能为用户提供便捷且高质量的视觉内容生成体验。
常见问题
1. Snap Video生成的视频质量如何?
Snap Video致力于生成高质量、高分辨率的视频,其性能在多个用户研究中表现优异。
2. 使用Snap Video需要什么样的输入?
用户只需提供一段描述性的文本,Snap Video便能够生成对应的视频内容。
3. Snap Video适合哪些类型的项目?
该模型适用于短视频制作、宣传片、在线课程等多个创意项目。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...

 粤公网安备 44011502001135号
粤公网安备 44011502001135号