Spirit LM是什么
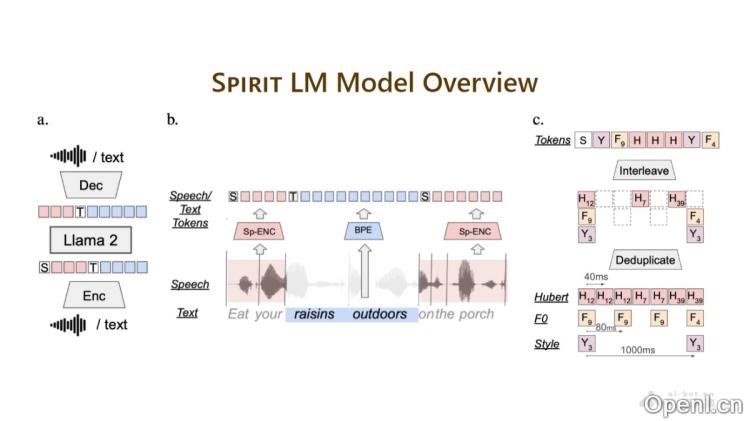
Spirit LM是Meta AI团队开发的一款多模态语言模型,具备无缝融合文本和语音数据的能力。该模型建立在一个经过预训练的文本语言模型之上,通过在文本和语音单元上持续训练,扩展了其在语音模态上的应用。Spirit LM分为两个版本:基础版(BASE)和表达版(EXPRESSIVE)。基础版专注于语音的语义单元,而表达版则在此基础上增加了音高和风格单元,以更好地模拟语音的情感表达。Spirit LM通过将语音和文本序列连接成一个统一的标记集,采用词级交错的方法进行训练,能够在少量样本的情况下,跨模态学习新任务,如自动语音识别(ASR)、文本到语音(TTS)和语音分类。
Spirit LM的主要功能
- 跨模态语言生成:Spirit LM能够生成文本和语音,实现无缝的切换体验。
- 语义与表达能力:结合文本模型的语义理解和语音模型的表达能力。
- 少量样本学习:可以在仅有少量样本的情况下迅速学习新任务,如ASR、TTS和语音分类。
- 情感保持:表达版(EXPRESSIVE)能够理解并生成具有特定情感色彩的语音和文本。
- 多模态理解:具备理解和生成跨模态内容的能力,例如将文本转换为语音或反之。
Spirit LM的技术原理
- 预训练与扩展:基于预训练的文本语言模型,通过在文本和语音单元上的持续训练,提升模型的语音处理能力。
- 交错训练:采用词级交错方法,将语音和文本序列整合为单一的标记集进行训练,确保语音与文本之间的对齐。
- 双模态标记:
- 基础版(BASE):使用语音语义单元(如HuBERT标记)。
- 表达版(EXPRESSIVE):在语义单元的基础上,结合音高(F0)和风格单元,以捕捉语音的情感表达。
- 编码与解码:
- 编码器:将语音转化为标记,使用HuBERT等模型进行语音编码。
- 解码器:将标记转换回原始模态(文本或语音)。
- 数据集与训练:
- 利用大规模的文本和语音数据集进行训练。
- 基于对齐的语音与文本数据集进行交错训练。
Spirit LM的项目地址
- 项目官网:speechbot.github.io/spiritlm
- GitHub仓库:https://github.com/facebookresearch/spiritlm
- arXiv技术论文:https://arxiv.org/pdf/2402.05755
Spirit LM的应用场景
- 语音助手:可嵌入智能设备中,提供语音交互功能,如回答询问、设置提醒及控制智能家居设备。
- 自动语音识别(ASR):将语音转化为文本,适用于语音转写、会议记录及语音命令系统。
- 文本到语音(TTS):将文本内容转换为语音输出,应用于有声读物、新闻播报及导航系统。
- 情感分析:分析语音或文本中的情感倾向,广泛应用于客户服务、市场研究及社交媒体监控。
- 语音翻译:实现语音输入的实时翻译,助力跨语言交流,适合国际会议和旅游场景。
常见问题
- Spirit LM支持哪些语言?:Spirit LM支持多种语言,具体取决于训练数据的可用性。
- 如何使用Spirit LM进行开发?:开发者可以访问GitHub仓库,获取相关文档和示例代码。
- Spirit LM的性能如何?:Spirit LM在多项任务中表现优异,具备强大的语义理解和表达能力。
- 是否支持离线使用?:Spirit LM的使用方式取决于具体部署,部分版本可支持离线操作。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...

 粤公网安备 44011502001135号
粤公网安备 44011502001135号