T2V-Turbo是一款由Google、加州大学圣塔芭芭拉分校及滑铁卢大学的研究团队共同开发的前沿文本到视频生成模型。该模型在预训练的T2V模型中,通过一致性蒸馏技术整合多种可微分奖励模型的反馈,以期达到快速生成高质量视频的目标。T2V-Turbo在只需四步推理的情况下,生成的视频质量超越了许多复杂模型,如Gen-2和Pika,且这一成绩在VBench评估平台上得到了验证。此外,T2V-Turbo的最新版本——T2V-Turbo-v2,进一步整合了高质量训练数据、奖励模型反馈和条件指导,显著提升了视频的视觉效果和文本与视频的匹配度。
T2V-Turbo是什么
T2V-Turbo是一种创新的文本到视频生成技术,旨在通过高效的推理步骤实现快速且高质量的视频输出。该模型的研发团队利用一致性蒸馏技术,成功整合了来自多种奖励模型的反馈,确保生成的视频不仅速度快,而且内容质量高。T2V-Turbo在生成过程中引入了新的优化方法,提升了文本与视频的对齐程度,使得生成的视频内容与输入的文本描述高度一致。
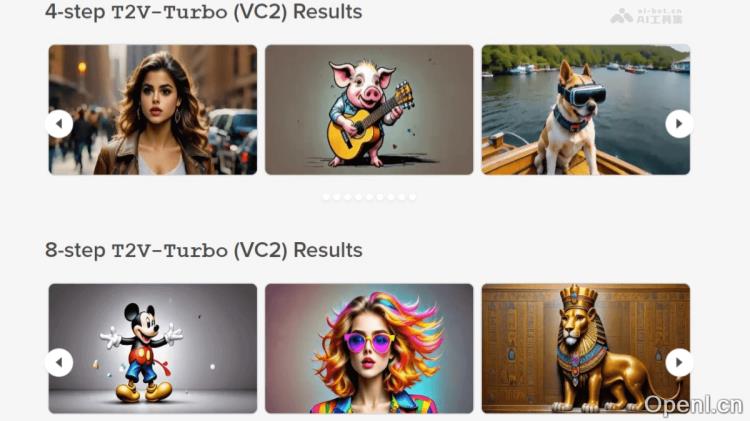
T2V-Turbo 的主要功能
- 迅速视频生成:通过减少推理步骤,显著缩短视频生成时间,提升制作效率。
- 卓越视频质量:在快速生成的同时,确保视频内容的高质量,满足视觉效果和内容准确性的要求。
- 文本与视频的精确对齐:生成的视频与输入的文本描述高度一致,确保文本意图能够准确转化为视频内容。
- 可微分奖励模型的融合:整合多种奖励模型的反馈,优化视频生成过程,使生成的视频更符合观众的审美期望。
- 内存优化:通过直接优化单步生成的奖励,避免传统迭代采样过程中的内存限制,使模型在资源有限的环境中同样高效运行。
T2V-Turbo 的技术原理
- 一致性蒸馏(Consistency Distillation, CD): T2V-Turbo利用一致性蒸馏技术加速视频生成,快速将生成过程中的任意点映射到初始点,减少所需的迭代步骤。
- 单步生成反馈: 该模型通过直接优化与单步生成相关的奖励,规避了迭代采样过程中的内存限制,从而快速生成高质量的视频。
- 混合奖励模型反馈: T2V-Turbo整合了图像-文本和视频-文本奖励模型的反馈,通过混合奖励机制全面提升视频的质量,确保其时间动态和过渡效果优秀。
- 反向传播梯度: 在训练过程中,T2V-Turbo基于单步生成过程中的反向传播梯度,将奖励模型的反馈有效整合到一致性蒸馏中,提升视频生成的质量和效率。
T2V-Turbo 的项目地址
- 项目官网:https://t2v-turbo.github.io/
- GitHub仓库:https://github.com/Ji4chenLi/t2v-turbo
- HuggingFace模型库:https://huggingface.co/collections/jiachenli-ucsb/t2v-turbo-6662d7f43d900927861fac82
- arXiv技术论文:https://arxiv.org/pdf/2405.18750
T2V-Turbo 的应用场景
- 娱乐和社交媒体:用户可以快速生成与文本描述相符的视频内容,并在YouTube、TikTok、Instagram等平台上发布,增加内容的趣味性和互动性。
- 电影和视频制作:电影制作人和视频编辑可以基于T2V-Turbo快速预览视频草图或生成特效场景的初步版本,从而加速创作流程。
- 新闻行业:新闻机构能够迅速生成新闻报道的背景视频,提高视觉吸引力和信息传递的效率。
- 教育和培训:教育组织可以利用T2V-Turbo生成生动的教育内容,如历史重现和科学实验模拟,使学习材料更具吸引力和易于理解。
- 营销和广告:企业能够快速制作产品介绍视频或广告宣传片,以更直观的方式展示产品特点,从而提升营销效果。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...

 粤公网安备 44011502001135号
粤公网安备 44011502001135号