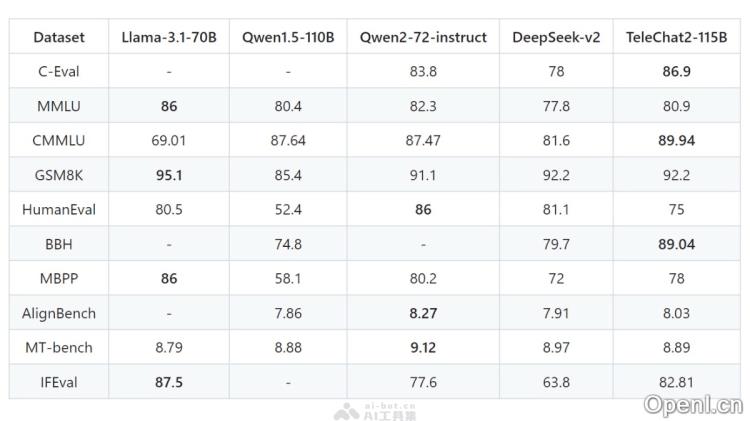
TeleChat2-115B是一款由中国电信人工智能研究院(TeleAI)开发的大型语言模型,属于星辰语义大模型系列。该模型基于国产算力进行训练,利用了10万亿Tokens的高质量中英文语料。与其前辈相比,TeleChat2-115B在通用问答、知识查询、编程辅助及数学计算等任务上表现出色,已在多个评测榜单中名列前茅,例如在C-Eval的Open Access模型综合榜单中荣获第一名。该模型的开源标志着国产大模型训练技术的一次重要飞跃,推动了相关技术的创新与产业应用。
TeleChat2-115B是什么
TeleChat2-115B是中国电信人工智能研究院(TeleAI)推出的一款先进的语言模型,隶属于星辰语义大模型系列。经过国产算力的训练,它采用了10万亿Tokens的优质中英文语料。相较于前代产品,TeleChat2-115B在多个领域的任务表现上都有显著提升,尤其是在通用问答、知识类查询、编程和数学计算等方面。该模型在各类评测中表现优异,如在C-Eval评测的Open Access模型综合榜单中排名第一。TeleChat2-115B的开源,使得国产大模型训练技术获得了重大进展,将为大模型技术的创新及其行业应用提供助力。
TeleChat2-115B的主要功能
- 文本生成:具备生成高质量中英文文本的能力。
- 多语言支持:能够处理和生成中英文文本,支持多种语言需求。
- 多格式多平台:提供多种格式和平台的权重文件,便于在不同环境中进行部署和使用。
- 高性能推理:支持单卡与多卡推理,优化长文本的推理能力。
- API和Web部署:提供API和Web接口,支持流式文本生成和多轮对话功能。
TeleChat2-115B的技术原理
- Decoder-only结构:模型采用标准的Decoder-only结构,专注于文本生成任务。
- Rotary Embedding:使用Rotary Embedding进行位置编码,有助于模型更好地捕捉序列数据中的相对位置信息。
- SwiGLU激活函数:引入SwiGLU激活函数,提升模型性能,相较于传统的GELU更具优势。
- RMSNorm的Pre-Normalization:采用基于RMSNorm的Pre-Normalization进行层标准化,增强模型训练的稳定性。
- 词嵌入和输出层参数分开:将词嵌入层与输出层参数分离,以改善训练稳定性和收敛性。
- GQA优化:选择GQA(Grouped Query Attention)方法,以减少attention部分的参数和计算量,提升训练及推理效率。
TeleChat2-115B的项目地址
- GitHub仓库:https://github.com/Tele-AI/TeleChat2
TeleChat2-115B的应用场景
- 智能客服:作为一款聊天机器人,能够提供客户咨询服务,及时解答用户问题。
- 内容创作:辅助用户进行写作,生成各类文章、故事和诗歌等文本内容。
- 语言翻译:提供高质量的中英文互译服务,满足多语言交流的需求。
- 教育辅导:帮助学生进行语言学习和作业辅导,助力理解复杂概念。
- 编程辅助:生成代码片段,协助开发者解决编程难题。
- 数据分析:能够处理和分析文本数据,提取关键有用信息。
- 智能搜索:增强搜索引擎的准确性,提供更为精准的搜索结果。
常见问题
- TeleChat2-115B的适用领域有哪些?:该模型广泛应用于智能客服、教育、编程、数据分析等多个领域。
- 如何使用TeleChat2-115B?:用户可以通过API或Web接口进行调用,并根据需求进行部署。
- TeleChat2-115B的开源代码在哪里可以找到?:代码可以在其GitHub仓库中获取。
- 该模型是否支持多语言?:是的,TeleChat2-115B支持高质量的中英文文本处理。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...

 粤公网安备 44011502001135号
粤公网安备 44011502001135号