Video-LLaVA2是一款由北京大学ChatLaw课题组研发的开源多模态智能理解系统,旨在提升视频和音频的理解能力。该模型通过创新的时空卷积(STC)连接器和音频处理分支,在视频问答、字幕生成等多个领域的基准测试中表现卓越,展现出与一些专有模型相媲美的性能。
Video-LLaVA2是什么
Video-LLaVA2是由北京大学ChatLaw课题组开发的一款开源多模态智能理解系统。它采用了先进的时空卷积(STC)连接器和音频分支,显著增强了对视频和音频内容的解析能力。该模型在视频问答和字幕生成等多个基准测试中表现优异,能够与许多专有模型相媲美,同时在音频和音视频问答任务中展现出卓越的多模态理解性能。
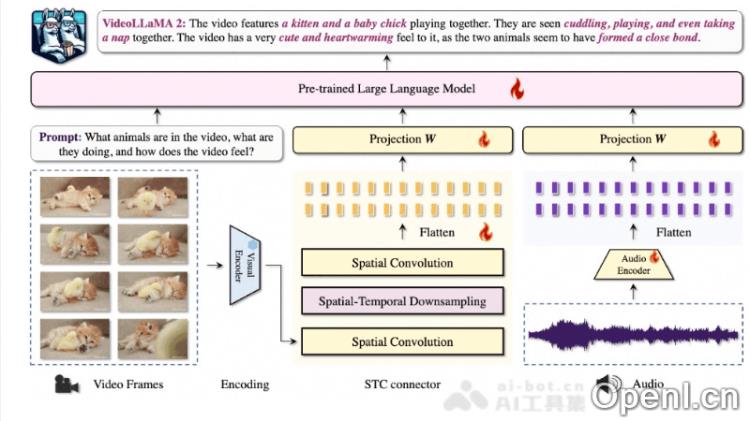
Video-LLaVA2的主要功能
- 视频理解:具备精准识别视频中视觉模式的能力,能够理解随时间变化的情境。
- 音频理解:整合了音频处理分支,能够分析视频中的音频信号,为理解提供更加丰富的上下文信息。
- 多模态交互:结合视觉和听觉信息,提升对视频内容的全面理解和分析能力。
- 视频问答:在多个视频问答任务中表现突出,能够准确回答与视频内容相关的问题。
- 视频字幕生成:为视频生成描述性字幕,精准捕捉关键信息和细节。
- 时空建模:通过STC连接器,模型能够更有效地捕捉视频中的时空动态与局部细节。
Video-LLaVA2的技术原理
- 双分支框架:模型采用视觉-语言分支和音频-语言分支的双分支结构,各自独立处理视频和音频数据,然后通过语言模型实现跨模态交互。
- 时空卷积连接器(STC Connector):一个专门设计的模块,用于捕捉视频数据中的复杂时空动态。相比传统的Q-former,STC连接器能够更有效地保留时空的局部细节,避免产生过多的视频标记。
- 视觉编码器:选择图像级的CLIP(ViT-L/14)作为视觉后端,与多种帧采样策略兼容,为帧到视频特征的聚合提供灵活方案。
- 音频编码器:使用诸如BEATs等先进的音频编码器,将音频信号转换为fbank频谱图,捕捉详细的音频特征和时间动态。
产品官网
- GitHub仓库:https://github.com/DAMO-NLP-SG/VideoLLaMA2?tab=readme-ov-file
- arXiv技术论文:https://arxiv.org/pdf/2406.07476
- 在线体验链接:https://huggingface.co/spaces/lixin4ever/VideoLLaMA2
Video-LLaVA2的应用场景
- 视频内容分析:自动分析视频内容,提取关键信息,适用于内容摘要、主题识别等。
- 视频字幕生成:为视频自动生成字幕或描述,提高视频的可访问性。
- 视频问答系统:构建智能系统,能够回答有关视频内容的问题,适合教育、娱乐等领域。
- 视频搜索与检索:通过理解视频内容,提供更加精准的视频搜索与检索服务。
- 视频监控分析:在安全监控领域,自动检测视频中的重要事件或异常行为。
- 自动驾驶:辅助理解道路情况,提升自动驾驶系统的感知与决策能力。
常见问题
- 如何开始使用Video-LLaVA2?:您可以从GitHub仓库下载代码,按照提供的说明准备环境和数据。
- Video-LLaVA2支持哪些数据格式?:模型支持多种视频和音频格式,具体要求可参考官方文档。
- 是否需要专业知识才能使用Video-LLaVA2?:虽然对模型的使用有一定的学习曲线,但提供的文档和示例代码将帮助您快速上手。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...

 粤公网安备 44011502001135号
粤公网安备 44011502001135号