VITA是腾讯优图实验室推出的全球首个开源多模态大语言模型(MLLM),能够处理视频、图像、文本和音频等多种形式的数据。基于Mixtral 8×7B模型,VITA扩展了中文词汇量并进行了双语指令微调,支持自然人机交互,无需特定唤醒词即可响应用户请求。其开源特性为学术界与工业界提供了宝贵的资源,推动了多模态理解和交互技术的进步。
VITA是什么
VITA是全球首个开源多模态大语言模型,由腾讯优图实验室研发,具备理解和处理视频、图像、文本与音频的能力。该模型基于Mixtral 8×7B架构,经过双语指令微调,特别增强了对中文方言的识别能力。VITA的开源特性不仅为学术研究提供了重要资源,也为工业应用的发展提供了支持。
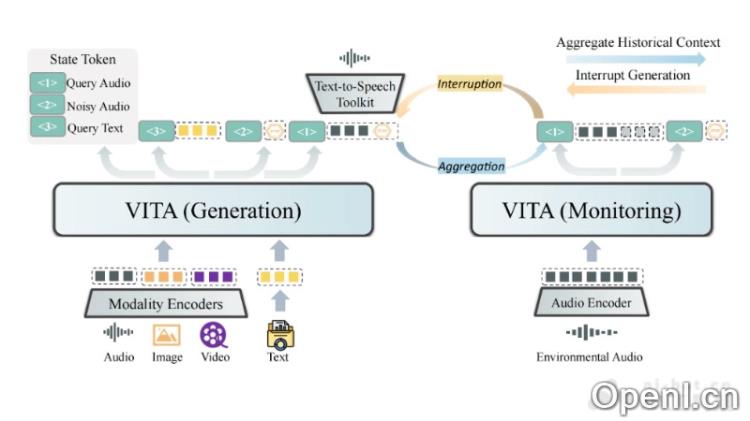
VITA的主要功能
- 多模态数据处理:VITA具备处理视频、图像、文本与音频等多种数据形式的能力,提供全面的信息处理解决方案。
- 双语能力:经过专门的双语指令微调,VITA在英语和中文之间游刃有余,尤其在中文方言的识别上表现突出。
- 自然对话交互:用户与VITA进行交流时,无需使用特定的唤醒词,模型能够根据上下文理解用户的意图,进行自然流畅的对话。
- 音频中断识别:即便在嘈杂环境中,VITA也能准确识别用户指令,提升交互的自然性与流畅度。
- 复式部署架构:VITA采用双模型的部署方式,一部分负责生成响应,另一部分持续监测环境输入,以确保准确及时的交互。
如何使用VITA
- 环境准备:确保具备运行VITA所需的硬件和软件环境,包括服务器、存储设备和网络连接。
- 获取模型:访问VITA的开源仓库,下载或克隆相应的代码库与预训练模型。
- 依赖安装:安装VITA运行所需的依赖库和工具,如Python及深度学习框架(例如PyTorch或TensorFlow)。
- 模型加载:将预训练的VITA模型加载至工作环境,准备进行交互或进一步训练。
- 数据准备:准备待处理的数据,包括文本、图像、视频或音频文件,确保其符合模型的输入要求。
VITA的项目地址
- 项目官网:https://vita-home.github.io/
- GitHub仓库:https://github.com/VITA-MLLM/VITA
- arXiv技术论文:https://arxiv.org/pdf/2408.05211
VITA的应用场景
- 智能家居控制:VITA能够理解语音指令,控制家庭中的智能设备,例如灯光、温度和安全系统等。
- 个人助理功能:提供日程管理、信息查询、邮件筛选与阅读摘要等功能,助力用户提高工作效率。
- 语言翻译与学习:支持多语言交流,帮助用户跨越语言障碍,促进国际间的沟通,辅助语言学习。
- 医疗咨询:分析病历和症状描述,提供初步的医疗建议,帮助医生进行诊断。
- 法律服务:解读法律文件,提供法律咨询,帮助用户理解复杂的法律条款。
常见问题
- VITA是否支持多种语言?是的,VITA经过双语微调,支持中文和英语,并具备对多种方言的理解能力。
- 如何获取VITA模型?用户可以通过VITA的GitHub仓库下载模型和相关代码。
- VITA的使用成本如何?由于VITA是开源的,用户可以免费使用,但需要有相应的硬件和软件支持。
- VITA支持哪些应用场景?VITA可应用于智能家居、个人助理、医疗咨询、法律服务等多种场景。
- 如何进行二次开发?用户可以在VITA的GitHub仓库中找到文档和示例,帮助进行二次开发和定制化。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...

 粤公网安备 44011502001135号
粤公网安备 44011502001135号