VoxInstruct 是由清华大学开源的一项先进的语音合成技术,能够根据人类的语言指令生成符合个人需求的高质量语音。该系统采用统一的多语言编解码器语言模型框架,将传统的文本到语音转换扩展到更广泛的人类指令到语音的应用。VoxInstruct 通过引入语音语义标记和多种无分类器指导策略,显著提升了语音合成的自然度和表现力,广泛适用于智能语音助手、有声读物及教育培训等多个场景。
VoxInstruct是什么
VoxInstruct 是由清华大学研发并开源的语音合成技术,旨在根据用户的语言指令生成高质量的语音输出。该技术通过统一的多语言编解码器语言建模框架,拓展了传统文本到语音的应用,将其提升至更广泛的人类指令转语音的层面。VoxInstruct 采用语音语义标记和多种无分类器指导策略,极大地增强了语音合成的自然感和表现力,支持多种语言的跨语言合成,适用于智能语音助手、有声读物、教育培训等多种应用场景。
VoxInstruct的主要功能
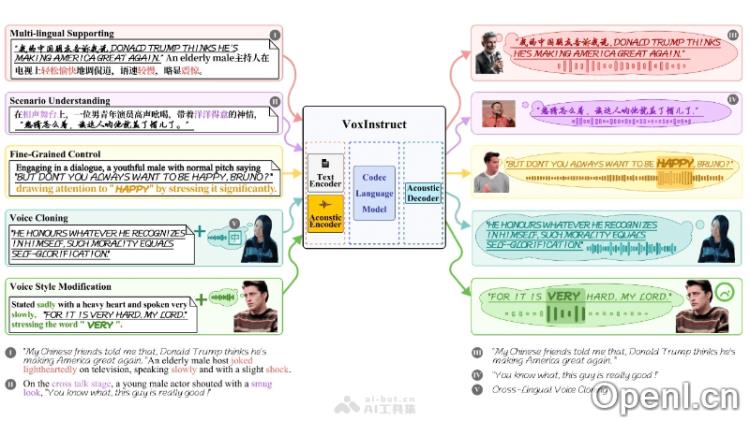
- 多语言支持:VoxInstruct 能够处理和生成多种语言的语音,支持跨语言的无缝合成。
- 指令到语音生成:用户可以直接通过语言指令生成语音,省去了复杂的预处理步骤。
- 语音语义标记:通过引入语音语义标记(Speech Semantic Tokens),模型能够更好地理解和提取指令中的语音信息。
- 无分类器指导策略:利用多种无分类器指导(Classifier-Free Guidance,CFG)策略,提升了模型对人类指令的理解能力和语音生成的可控性。
- 情感和风格控制:VoxInstruct 能够根据指令中所包含的情感和风格描述,生成相应情感和风格的语音。
VoxInstruct的技术原理
- 统一的多语言编解码器语言模型框架:VoxInstruct 采用编解码器框架来处理和理解多语言指令,从而生成对应的语音输出。
- 预训练的文本编码器:该技术基于预训练的文本编码器(如 MT5),用于理解和处理自然语言输入,捕捉语言的深层语义信息。
- 语音语义标记(Speech Semantic Tokens):这是一种中间表示形式,可以将文本指令有效映射到语音内容,帮助模型提取关键信息并指导语音生成。
- 无分类器指导(Classifier-Free Guidance,CFG)策略:VoxInstruct 综合了 CFG 策略,以增强模型对人类指令的反应能力,提高语音合成的自然性和准确性。
- 神经编解码器模型:Encodec 被用作声学编码器,提取声学特征作为中间表示,随后用于生成最终的语音波形。
VoxInstruct的项目地址
VoxInstruct的应用场景
- 个性化语音反馈:智能助手可以根据用户的偏好,设置不同的语音风格,如性别、年龄和口音等,利用 VoxInstruct 生成个性化的语音反馈。
- 情感交互:通过分析用户指令及上下文,VoxInstruct 能生成带有情感色彩的语音,例如快乐、悲伤或中性,从而使交互更加自然和生动。
- 多语言支持:在多语言环境中,VoxInstruct 可以支持多种语言的语音合成,帮助智能助手更好地服务于不同语言背景的用户。
- 语音导航系统:VoxInstruct 可以在智能导航系统中生成清晰的语音指令,提供实时的路线指引和交通信息。
常见问题
- VoxInstruct支持哪些语言?:VoxInstruct 支持多种语言的处理与生成,具体语言列表可在项目官网查看。
- 如何使用VoxInstruct?:用户可以访问GitHub仓库获取源代码和使用说明,按照文档进行设置和调用。
- VoxInstruct的语音质量如何?:VoxInstruct 通过先进的合成技术,生成的语音自然流畅,具有高度的表现力。
- 可以定制语音风格吗?:是的,VoxInstruct 支持根据指令中的情感和风格描述生成定制的语音。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...

 粤公网安备 44011502001135号
粤公网安备 44011502001135号