Whisper-Medusa是一款由aiOla推出的开源AI语音识别模型,融合了OpenAI的Whisper技术与aiOla的创新,显著提升了语音处理的速度和准确度,尤其优化了英语识别,支持超过100种语言,广泛适用于翻译、金融、旅游等行业。
Whisper-Medusa是什么
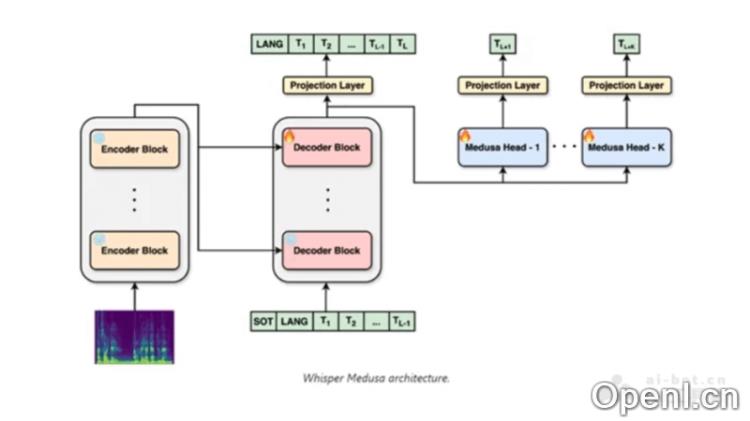
Whisper-Medusa是aiOla开发的开源AI语音识别模型,它巧妙结合了OpenAI的Whisper技术与aiOla的独特创新。通过引入多头注意力机制,该模型实现了并行处理,推理速度提高了平均50%。Whisper-Medusa专门针对英语进行了优化,并支持超过100种语言,适合在翻译、金融、旅游等多个领域中应用。模型在LibriSpeech数据集上经过训练,展现出卓越的性能与准确性,同时利用弱监督方法减少了对大规模手动标注数据的需求。aiOla计划进一步扩展模型的多头注意力机制,以实现更高的处理效率。

Whisper-Medusa的主要功能
- 快速语音识别:得益于多头注意力机制,Whisper-Medusa能够并行处理语音数据,转录速度比传统模型提高50%。
- 高精度识别:在提高速度的同时,Whisper-Medusa依然保持与原始Whisper模型相同的高准确度。
- 多语言兼容:该模型支持超过100种语言的转录与翻译,适用于多种语言环境。
- 弱监督训练:通过弱监督方法进行训练,减少了对大量人工标注数据的依赖。
- 强适应性:模型能够理解特定行业的术语和口音,适合不同的声学环境。
Whisper-Medusa的技术原理
- 多头注意力机制:Whisper-Medusa采用多头注意力机制,允许模型同时处理多个数据单元,显著提升推理速度。
- 弱监督训练:训练过程中,Whisper-Medusa利用弱监督方法,原始Whisper模型的主要组件被冻结,同时训练额外参数,通过伪标签训练Medusa的额外token预测模块。
- 并行计算:模型的每个“头”可以独立计算注意力分布,进而并行处理输入数据,提升推理速度和表达能力。
- 优化损失函数:训练中,损失函数同时考虑预测准确性与效率,鼓励模型在保证精度的前提下加快预测速度。
- 稳定性与泛化能力:为确保模型在训练中稳定收敛,aiOla引入学习率调度、梯度裁剪和正则化等多种方法以防止过拟合。
Whisper-Medusa的项目地址
- 项目官网:https://aiola.com/blog/introducing-whisper-medusa/
- GitHub仓库:https://github.com/aiola-lab/whisper-medusa
- HuggingFace模型库:https://huggingface.co/aiola/whisper-medusa-v1
Whisper-Medusa的应用场景
- 语音识别(ASR):Whisper-Medusa可用于实时将语音转换为文本,适合会议记录、讲座转录及播客制作等场合。
- 多语言翻译:支持超过100种语言,适用于实时翻译服务,促进跨语言交流及国际会议。
- 内容监控与分析:在广播、电视及网络媒体中,Whisper-Medusa可自动生成字幕和内容摘要,并进行内容监控。
- 客户服务:在呼叫中心,Whisper-Medusa能够提高客户服务效率,通过自动语音识别快速响应客户需求。
- 医疗记录:在医疗领域,Whisper-Medusa可快速准确地转录医生的诊断及病人的病史,提高医疗记录的效率。
- 法律与司法:在法庭记录与法律研究中,Whisper-Medusa可帮助快速生成准确的文字记录。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...

 粤公网安备 44011502001135号
粤公网安备 44011502001135号