xGen-MM是一款由Salesforce开发的开源多模态AI模型,具备处理交错数据的能力,能够同时理解和生成文本与图像等多种数据形式。通过对海量图像和文字数据的学习,xGen-MM在视觉语言任务上表现出色,并通过开源模型、数据集以及微调代码库,持续推动模型性能的提升。
xGen-MM是什么
xGen-MM是Salesforce推出的一款开源多模态AI模型,具备处理交错数据的能力,能够同时理解和生成文本、图像等多种数据类型。通过学习大量的图片和文字信息,xGen-MM在视觉语言任务上展现出强大的性能,同时通过开源模型、数据集和微调代码库,促进模型能力的不断提升。

xGen-MM的主要功能
- 多模态理解:xGen-MM能够同时处理和理解图像与文本信息,支持回答有关视觉内容的问题。
- 大规模数据学习:通过丰富多样的数据训练,xGen-MM能够捕捉到复杂的视觉与语言模式。
- 高效生成:不仅理解输入信息,xGen-MM还能够生成文本,如根据图像编写描述或提供回答。
- 开源可访问性:xGen-MM的模型、数据集和代码均为开源,研究人员和开发者可以自由访问和使用这些资源,构建自己的应用。
- 微调功能:用户可以根据特定需求对xGen-MM进行微调,以适应不同的应用场景。
xGen-MM的项目地址
- GitHub仓库:https://github.com/salesforce/LAVIS/tree/xgen-mm
- Hugging Face模型库:https://huggingface.co/Salesforce/xgen-mm-phi3-mini-instruct-interleave-r-v1.5
- arXiv技术论文:https://arxiv.org/pdf/2408.08872
xGen-MM的技术原理
- 多模态学习:xGen-MM通过训练实现图像和文本数据的同时理解,从而融合视觉和语言信息。
- 大规模数据集:该模型在多样化的大规模数据集上进行训练,涵盖丰富的图像及其描述。
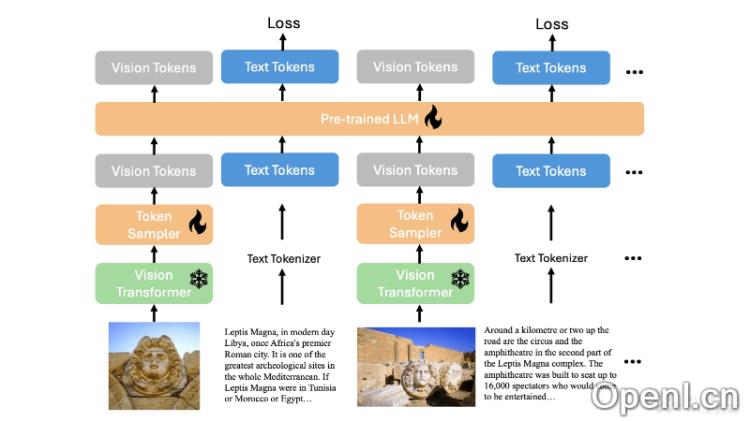
- 视觉令牌采样器:采用高效的视觉令牌采样器(如Perceiver架构)来处理图像数据,支持模型以可扩展的方式处理不同分辨率的图像。
- 预训练语言模型:结合预训练的大型语言模型(如Phi-3模型),在大量文本数据上进行训练,具备强大的语言理解能力。
- 统一的训练目标:通过单一的自回归损失函数简化训练过程,专注于多模态上下文中预测文本令牌。
- 指令微调:该模型可通过指令微调更好地理解和执行用户的查询,在特定任务上进行额外训练。
- 后训练优化:包括直接偏好优化(DPO)和安全性微调,以提高模型的实用性、减少幻觉效应并增强安全性。
- 开源与可定制性:xGen-MM的代码、模型和数据集均为开源,允许社区成员根据需求进行定制和进一步开发。
xGen-MM的应用场景
- 图像描述生成:自动为图片生成描述性文字,适用于社交媒体和相册管理等场景。
- 视觉问答:回答与图像内容相关的问题,适用于教育和电子商务领域的产品信息提供。
- 文档理解:解析和理解文档中的图像与文字,适用于自动化文档处理和信息检索。
- 内容创作:在创作过程中辅助用户,如自动生成故事板和设计概念图等。
- 信息检索:结合图像与文本,提高搜索结果的相关性和准确性。
常见问题
- xGen-MM是如何工作的?:xGen-MM通过多模态学习结合图像和文本信息,能够理解并生成相关内容。
- 如何访问xGen-MM?:用户可以通过提供的GitHub和Hugging Face链接获取xGen-MM的代码和模型。
- xGen-MM能用于哪些行业?:xGen-MM适用于教育、电子商务、社交媒体、内容创作等多个行业。
- 如何对xGen-MM进行微调?:用户可以根据自身需求,利用开源的微调代码库对模型进行调整。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...

 粤公网安备 44011502001135号
粤公网安备 44011502001135号