CogView3是一款由清华大学与智谱AI联合开发的开源AI图像生成模型,采用创新的中继扩散技术。该模型通过分阶段生成图像,首先创建低分辨率图像,然后利用中继超分辨率技术进行提升,从而显著提高生成效率并降低成本。CogView3在图像生成的质量和速度方面都超越了现有的开源模型SDXL,能够在保持细节的同时大幅缩短推理时间。此外,CogView3的精简版本在仅需SDXL十分之一的推理时间下,依然能保持相当的性能,展现出其在图像生成领域的突出优势。
CogView3是什么
CogView3是一个开源的AI图像生成模型,由清华大学与智谱AI共同推出,采用了先进的中继扩散技术。该模型分阶段地生成图像,首先生成低分辨率图像,然后通过中继超分辨率技术将其提升至高分辨率,从而实现更高的生成效率和更低的成本。CogView3在生成图像的质量和速度上均优于现有的开源模型SDXL,能够在保持图像细节的同时显著减少推理时间。此外,CogView3的轻量化版本在推理时间上比SDXL快约50%,而其精简版的速度更是快了十倍,充分显示了其在图像生成领域的显著优势。
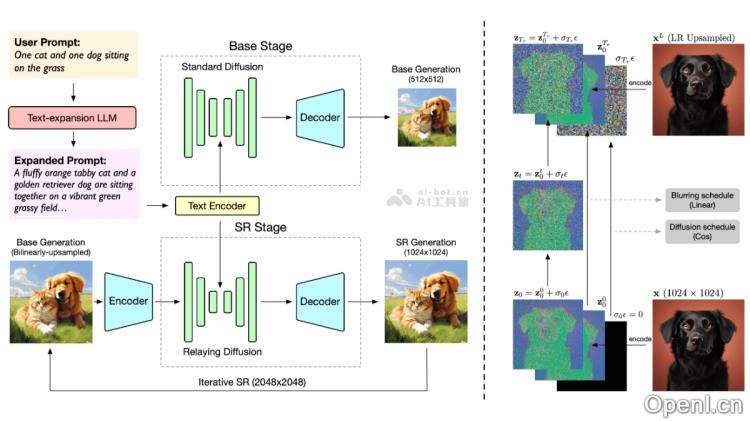
CogView3的主要功能
- 中继扩散技术:采用逐层生成的方式,首先产生低分辨率图像,再通过中继超分辨率技术提升至高分辨率。
- 高性能:在用户评估中,CogView3的生成质量优于当前最先进的模型SDXL,并且推理速度更快。
- 高效率:CogView3的推理时间大约比SDXL快50%,其精简版本更是快了十倍。
- 多分辨率支持:支持生成从512×512到2048×2048的多种分辨率图像。
CogView3的技术原理
- 级联框架:采用多阶段的生成过程,通过级联方式逐步提升图像分辨率。
- 中继扩散:在生成低分辨率图像后,添加高斯噪声并从中继点开始扩散,生成高分辨率图像。
- Zero-SNR扩散噪声调度:采用优化的噪声调度方法,提升生成图像的质量及速度。
- 联合文本-图像注意力机制:结合文本与图像信息,通过注意力机制增强生成图像与文本描述的一致性。
- 变分自编码器(VAE):使用VAE将高维像素空间压缩至低维潜在空间,以降低计算成本。
- 蒸馏技术:利用蒸馏过程,减少模型推理时所需的采样步骤,同时保持生成质量。
CogView3的项目地址
- GitHub仓库:https://github.com/THUDM/CogView3
- arXiv技术论文:https://arxiv.org/pdf/2403.05121
- CogView-3-Plus:https://openi.cn/cogview-3-plus/
- 智谱清言产品体验:https://openi.cn/sites/2005.html
CogView3的应用场景
- 艺术创作:艺术家和设计师可利用CogView3生成独特的艺术作品或设计草图,以激发创作灵感。
- 数字娱乐:在游戏和电影制作过程中,模型能够快速生成场景概念图或角色设计,助力前期制作。
- 广告和营销:营销人员使用CogView3设计引人注目的广告图像,以满足多样化的视觉需求。
- 虚拟试穿:在时尚行业,用户可以通过上传图片与选择样式,利用CogView3生成服装试穿效果。
- 个性化礼品定制:为用户提供个性化的礼品设计服务,如定制T恤、杯子或手机壳等,满足个性化需求。
常见问题
如果您对CogView3有任何疑问,欢迎查阅项目的GitHub页面或技术论文,获取更多详细信息和支持。
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章
暂无评论...
打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
 粤公网安备 44011502001135号
粤公网安备 44011502001135号