F5-TTS是一款由上海交通大学开源的高效文本到语音(TTS)系统,采用流匹配的非自回归生成方法,并结合了扩散变换器(DiT)技术。该系统能够在无额外监督的情况下,利用零样本学习迅速生成自然流畅且忠实于原文的语音。F5-TTS支持多种语言合成,包括中文和英文,特别适合长文本的语音合成。此外,它还具备情感控制和速度调节功能,能够根据文本内容和用户需求灵活调整合成语音的表现。
F5-TTS是什么
F5-TTS是由上海交通大学开源的一款高效文本到语音(TTS)系统,基于流匹配的非自回归生成方法,结合扩散变换器(DiT)技术。该系统可以在没有额外监督的条件下,通过零样本学习快速生成自然且流畅的语音,紧密贴合原文。F5-TTS支持多语言合成,特别适合长文本的语音处理。系统具备情感控制功能,可以根据文本内容调整合成语音的情感表现,同时也支持语音播放速度的调节。经过在10万小时的大规模数据集上训练,F5-TTS展现出卓越的性能和强大的泛化能力,广泛应用于有声读物、语音助手、语言学习、新闻播报以及游戏配音等多种场景。
F5-TTS的主要功能
- 零样本声音克隆:无需特定说话人的数据即可模仿任何人的声音。
- 语速控制:用户可根据需求调整语音生成的速度,实现精准的语音播放速度调节。
- 情感表现调控:合成语音的情感色彩可根据文本内容进行调节,使机器生成的语音更具人性化表现。
- 长文本合成能力:支持对长文本进行连续语音合成,适合长篇内容的朗读和播报。
- 多语言合成支持:能处理并生成中文、英文等多种语言的语音,展现出良好的多语言合成能力。
- 大规模数据训练:在10万小时的大规模数据集上进行训练,确保模型具有卓越的泛化能力和自然的语音合成效果。
F5-TTS的技术原理
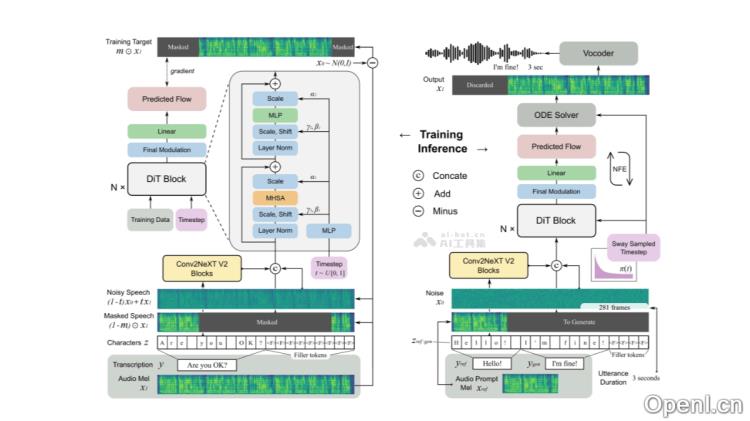
- 流匹配(Flow Matching):F5-TTS通过流匹配目标训练模型,将简单的概率分布(如标准正态分布)转变为复杂的数据分布。这一过程确保模型能够处理从初始分布到目标分布的整个转换。
- 扩散变换器(DiT):作为模型的核心网络,DiT能够处理序列数据,并在生成过程中逐步去除噪声,输出清晰的语音信号。
- ConvNeXt V2:F5-TTS基于ConvNeXt V2优化文本表示,使其更容易与语音特征对齐,从而提高语音合成的质量和自然度。
- Sway Sampling策略:在推理过程中使用的流步骤采样策略,通过非均匀采样提升模型性能和效率,尤其在生成语音的初期阶段,有助于模型更准确地捕捉目标语音的轮廓。
- 端到端系统设计:F5-TTS采用简单直接的系统设计,从文本输入到语音输出,省略了传统复杂设计,简化了模型的训练和推理过程。
F5-TTS的项目地址
- GitHub仓库:https://github.com/SWivid/F5-TTS
- HuggingFace模型库:https://huggingface.co/SWivid/F5-TTS
- arXiv技术论文:https://arxiv.org/pdf/2410.06885
- 在线体验Demo:https://huggingface.co/spaces/mrfakename/E2-F5-TTS
F5-TTS的应用场景
- 有声读物与播客:将电子书或文章转化为有声书,便于视力受限的人士或喜爱听书的用户使用。
- 语音助手与机器人:为智能设备和在线服务提供自然的语音反馈,提升用户体验。
- 语言学习与教育:帮助学习者练习发音和听力,提供语言学习的辅助工具。
- 新闻与媒体:自动生成新闻报道的语音版本,为广播电台和在线新闻平台提供内容生产的自动化解决方案。
- 客户服务:在客户服务系统中应用,提供自动语音响应,改善客户体验。
常见问题
对于F5-TTS用户而言,常见问题包括如何安装和使用该系统、如何调整语速和情感表现、以及如何处理不同语言的语音合成等。用户可通过访问项目的GitHub和HuggingFace页面获取详细的文档和支持。
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章
暂无评论...
打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
 粤公网安备 44011502001135号
粤公网安备 44011502001135号