LongWriter 是清华大学与智谱AI合作开发的一款长文本生成模型,具备产生超过10,000字的连贯文本的能力,并且该项目已实现开源。通过深入分析现有大型语言模型的输出限制,LongWriter 创建了“LongWriter-6k”数据集,成功拓展了AI模型的生成能力。此外,LongWriter 采用了直接偏好优化(DPO)技术,以提升生成文本的质量并更好地遵循给定的长度限制。
LongWriter是什么
LongWriter 是一款由清华大学与智谱AI联合推出的长文本生成模型,能够生成超过10,000字的连贯文本,目前该项目已开源。为了分析现有大型语言模型在输出长度上的局限性,LongWriter 团队构建了“LongWriter-6k”数据集,从而有效提升了AI模型的输出能力。该模型还采用了直接偏好优化(DPO)技术,旨在提升输出文本的质量和对指令长度限制的遵循能力。

LongWriter的主要功能
- 超长文本生成:LongWriter 能够生成超过10,000字的连贯文本,突破了以往AI模型在文本长度上的限制。
- 数据集构建:通过创建“LongWriter-6k”数据集,模型获得了包含从2,000到32,000字不等的写作样本,为训练提供了丰富的长文本数据。
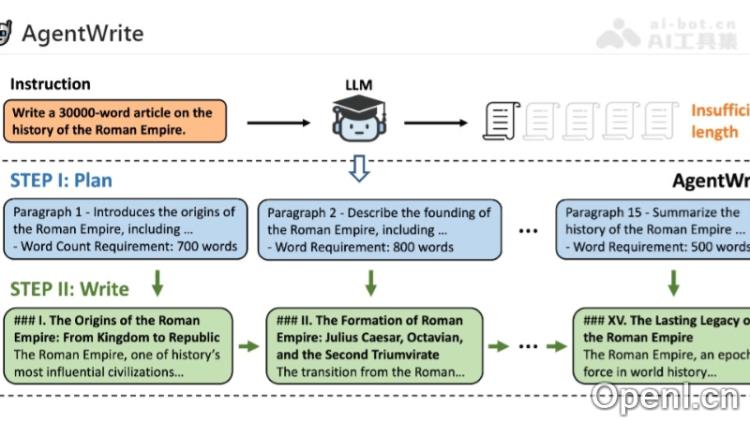
- AgentWrite方法:利用现有大型语言模型(LLMs)自动生成超长输出的SFT数据,采用分而治之的策略,有效提升了模型的长文本生成能力。
- 直接偏好优化(DPO):通过DPO技术,进一步优化模型,提升输出的质量并确保遵循长度约束。
LongWriter的技术原理
- 长上下文处理能力:LongWriter 基于长上下文大型语言模型(LLMs),具备处理超过100,000个token历史记录的能力。
- 输出长度限制分析:通过对现有模型在不同查询下的最大输出长度进行分析,LongWriter 识别到输出长度限制主要来源于监督式微调(SFT)数据集的特性。
- 监督式微调(SFT):在SFT阶段,LongWriter 使用“LongWriter-6k”数据集进行训练,使模型学习生成更长文本的能力。
LongWriter的项目地址
- GitHub仓库:https://github.com/THUDM/LongWriter
- HuggingFace模型库:https://huggingface.co/THUDM/LongWriter-glm4-9b
- arXiv技术论文:https://arxiv.org/pdf/2408.07055
如何使用LongWriter
- 环境配置:确保拥有足够的计算资源以运行LongWriter模型,包括高性能GPU和充足的内存。
- 获取模型:访问GitHub以获取LongWriter的开源代码和模型。
- 安装依赖:根据项目文档安装所需的依赖库和工具,涵盖深度学习框架和数据处理库。
- 数据准备:准备适合LongWriter处理的长文本数据,并进行预处理,确保符合模型的输入要求。
- 模型加载:加载预训练的LongWriter模型,或根据自身数据进行进一步微调。
- 编写提示:编写清晰的提示或指令,以指导模型生成特定内容的文本。
- 生成文本:使用模型提供的接口或API,输入提示并启动文本生成过程。
LongWriter的应用场景
- 学术研究:LongWriter 可协助学者和研究人员撰写长篇学术论文、研究报告或文献综述。
- 内容创作:作家和内容创作者可利用LongWriter生成小说、剧本或其他创意写作的初稿。
- 出版行业:出版社可借助LongWriter辅助编辑、校对工作,或自动生成书籍内容。
- 教育领域:教育工作者可使用LongWriter生成教学材料、课程内容或学习指南。
- 新闻媒体:新闻机构可利用LongWriter快速生成新闻报道、深度分析文章或专题报道。
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章
暂无评论...
打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
 粤公网安备 44011502001135号
粤公网安备 44011502001135号