SAM 2(Segment Anything Model 2)是Meta开发的一款先进AI对象分割模型,专注于实时处理图像和视频的分割任务。它具备优异的零样本泛化能力,可以准确识别并分割未见过的对象。此外,它通过一个统一的架构同时支持图像和视频的处理,提升了应用的灵活性。SAM 2还具备交互式提示功能,允许用户通过简单的点击或框选来指导分割过程。该模型已开源,推动了视频编辑、自动驾驶、医学成像等多个领域的应用进展。
SAM 2是什么
SAM 2(Segment Anything Model 2)是Meta推出的一款AI对象分割模型,旨在实时处理图片和视频中的对象分割。它具有卓越的零样本泛化能力,能够有效分割未知对象,并且通过统一的架构同时处理图像和视频。SAM 2的设计支持用户交互,通过点击或框选来指导分割过程。该模型已开源,推动了AI在视频编辑、自动驾驶和医学成像等领域的广泛应用。
SAM 2的主要功能
- 集成处理能力:SAM 2能同时处理静态图像和动态视频的分割任务,提升了应用的灵活性和效率。
- 高效实时处理:具备高效的实时处理能力,每秒可分析多达44帧的图像,满足快速反馈需求的应用场景,如视频编辑和增强现实。
- 适应性强:该模型能够识别并分割在训练阶段未曾出现过的新物体,展现出良好的适应性。
- 用户交互改进:用户可以通过反馈告诉SAM 2哪些地方表现良好,哪些地方需要改进,从而提升模型的准确性。
- 复杂场景解析:在复杂或模糊的场景中,SAM 2能够提供多个分割选项,智能地解析和区分重叠或部分遮挡的对象。
SAM 2的技术原理
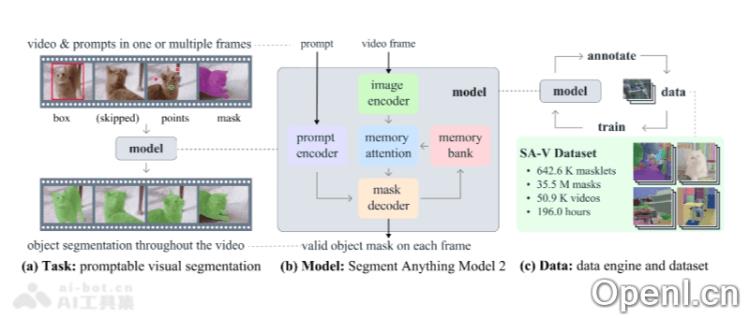
- 统一模型架构:SAM 2将图像和视频分割功能整合在一个模型中,基于用户提示,通过点、边界框或掩码来指定感兴趣的对象。
- 高级处理机制:该模型设计有处理视频分割中常见问题的机制,如物体遮挡。使用复杂的记忆机制来跟踪各帧中的物体,确保连续性。
- 模型架构:包括图像和视频编码器、提示编码器、记忆机制(记忆编码器、记忆库和记忆注意力模块)以及掩码解码器,这些组件协同工作以提取特征、处理用户提示、存储过去帧的信息,并生成最终的分割掩码。
- 记忆机制和遮挡处理:记忆机制使SAM 2能够处理时间依赖性和遮挡问题。当物体移动或被遮挡时,模型可以依赖记忆库预测对象的位置和外观。
- 多掩码模糊解决:在存在多个可能的分割对象时,SAM 2能够生成多个掩码预测,提高对复杂场景的准确度。
- SA-V 数据集:为了训练SAM 2,开发了SA-V数据集,成为目前最大、最具多样性的视频分割数据集之一,涵盖超过51,000个视频和600,000个掩码注释,提供了前所未有的多样性和复杂性。
- 提示视觉分割任务:SAM 2设计为可以接受视频中任意一帧的输入提示,定义要预测的时空掩码,并能够依据这些提示即时预测当前帧的遮罩,并在时间上进行传播,生成目标对象在所有视频帧中的masklet。
SAM 2的项目地址
- 项目官网:https://ai.meta.com/sam2/
- 体验Demo:https://aidemos.meta.com/
- GitHub仓库:https://github.com/facebookresearch/segment-anything-2
- HuggingFace模型库:https://huggingface.co/models?search=facebook/sam2
- arXiv技术论文:https://arxiv.org/abs/2408.00714
SAM 2的应用场景
- 视频编辑:在视频后期制作中,SAM 2可以迅速分割视频中的对象,帮助编辑者从复杂背景中提取特定元素,并进行特效添加或替换。
- 增强现实(AR):在增强现实应用中,SAM 2能够实时识别和分割现实世界中的对象,为用户叠加虚拟信息或图像。
- 自动驾驶:在自动驾驶系统中,SAM 2可以精确识别和分割道路、行人、车辆等,提高导航和避障的准确性。
- 医学成像:在医学领域,SAM 2可以辅助医生在医学影像中分割和识别病变区域,为诊断和治疗计划提供支持。
- 内容创作:对于内容创作者,SAM 2能够在视频或图像中快速选取特定对象,拓展创作的可能性。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...

 粤公网安备 44011502001135号
粤公网安备 44011502001135号