Self-Lengthen是阿里巴巴千问团队推出的一款创新迭代训练框架,旨在增强大型语言模型(LLMs)生成长文本的能力。该框架通过生成器和扩展器两种角色的协同作用,生成器负责初步响应,而扩展器则对这些响应进行拆分和扩展,从而产生更为丰富的长文本。Self-Lengthen的独特之处在于它不需要额外的数据或专有模型,而是充分利用LLMs的内在知识,有效解决了长文本生成过程中的训练挑战。
Self-Lengthen是什么
Self-Lengthen是阿里巴巴千问团队推出的创新的迭代训练框架,能提升大型语言模型(LLMs)生成长文本的能力。框架基于两个角色,生成器和扩展器协同工作,生成器负责生成初始响应,扩展器将响应拆分、扩展产生更长的文本。整个过程不断迭代,逐步训练模型处理更长的输出。Self-Lengthen无需额外数据或专有模型,基于LLMs的内在知识和技能,有效解决长文本生成的训练缺陷问题。
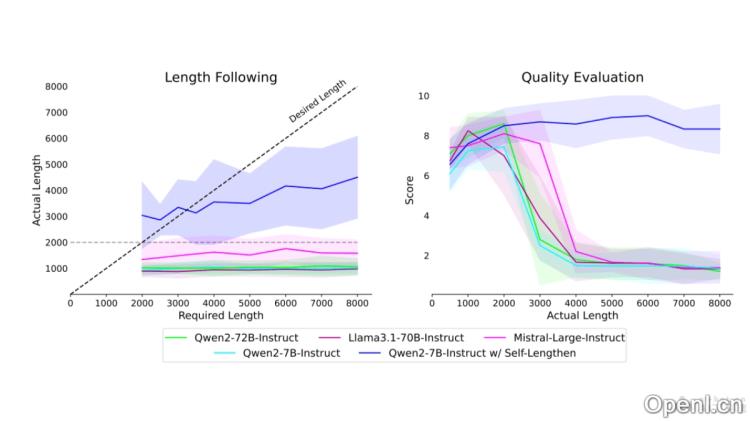
Self-Lengthen的主要功能
- 增强输出长度:使LLMs能够生成比传统训练方法更为丰富的长文本。
- 维护内容质量:在扩展文本长度的同时,确保生成内容的连贯性和相关性不受影响。
- 无需额外数据:不依赖外部数据源,充分利用模型自身的知识和技能。
- 迭代训练:通过反复迭代,逐步提升模型处理长文本的能力。
- 灵活性:适用于多种长文本生成任务,包括文学创作、学术研究等领域。
Self-Lengthen的技术原理
- 生成器(Generator)和扩展器(Extender):
- 生成器:负责生成初始的短文本响应。
- 扩展器:将生成器的输出作为输入,扩展成长文本。
- 迭代训练过程:
- 通过反复迭代,逐渐增强生成器和扩展器在处理长文本方面的能力。
- 在每次迭代中,扩展器尝试将生成器的输出进一步扩展,同时微调生成器以便直接生成更长的文本。
- 指令增广:运用自指导技术丰富和多样化训练指令,更有效地引导模型生成长文本。
- 两阶段扩展方法:
- 第一阶段:扩展器扩展生成器输出的前半部分。
- 第二阶段:利用第一阶段的扩展成果指导剩余部分的扩展,确保整个文本的连贯性。
- 微调模型:基于扩展得到的更长文本对生成器和扩展器进行微调,以便在未来的迭代中生成更长的文本。
- 质量控制:通过规则和评估机制确保生成的长文本质量,避免重复和无意义的扩展。
Self-Lengthen的项目地址
- GitHub仓库:https://github.com/QwenLM/Self-Lengthen
- arXiv技术论文:https://arxiv.org/pdf/2410.23933
Self-Lengthen的应用场景
- 创意写作:可用于生成小说、故事、剧本等长篇文学作品。
- 学术研究:帮助研究者撰写学术论文、技术报告和研究提案。
- 新闻媒体:用于撰写新闻报道、深度文章和专题报道,提供详尽的内容覆盖。
- 教育内容开发:创建教育材料、课程内容和教科书,提供深入的教学资源。
- 商业文案:用于撰写营销文案、广告内容和商业计划书等商业文档。
常见问题
- Self-Lengthen是否需要大量的训练数据?
不需要,Self-Lengthen能够充分利用现有的LLMs内在知识,而无需额外的数据。
- 如何保证生成文本的质量?
通过质量控制机制和评估标准,确保生成的长文本具备良好的连贯性和相关性。
- Self-Lengthen适用于哪些领域?
Self-Lengthen广泛适用于创意写作、学术研究、新闻媒体、教育内容开发和商业文案等多个领域。
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章
暂无评论...
打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
 粤公网安备 44011502001135号
粤公网安备 44011502001135号