AIGC动态欢迎阅读
原标题:如果我搬出RLHF+GAN这个设定,你如何应对
关键字:模型,数据,腾讯,样本,方法
文章来源:算法邦
内容字数:10403字
内容摘要:
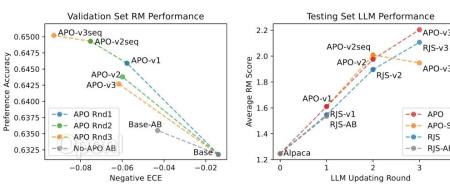
前阵子腾讯AI Lab悄悄挂出了一篇文章:Adversarial Preference Optimization (APO)[1],看到设定我就惊呆了:RLHF+GAN,难道还嫌RLHF本身不够难训吗?但读下来发现作者其实是想解决RLHF一个很重要的问题,而且给出的方法既fancy又优雅。
下面,我们直接有请一作本人程鹏宇大佬来讲一下心路历程?。
注:文中有公式,请切换到白色背景查看。01RLHF辛酸泪先从RLHF的任务讲起吧,RLHF的全称是 reinforcement learning from human feedback。字面意思就是用RL的方法把大模型训练得更加符合人们的反馈。这里反馈其实就是人们对大模型回复质量的评价。还是蛮主观的一件事,尤其是对一些开放性问题,其实很难讲大模型的回复到底好到什么程度。但是如果对同一个问题给出两个回复,通过对比人们至少能在两个回复里挑出一个更好的,这大概就是所谓的“没有比较就没有伤害”吧。
于是人类反馈数据都长成了一个问题和两个比较过的回复的格式。因为每次反馈就是从两个回复里挑个更好的,代表了标注人员的偏好,所以RLHF解决的任务也被称为偏
联系作者
文章来源:算法邦
作者微信:allplusai
作者简介:「算法邦」,隶属于智猩猩,关注大模型、生成式AI、计算机视觉三大领域的研究与开发,提供技术文章、讲座、在线研讨会。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。