AIGC动态欢迎阅读
原标题:今日arXiv最热NLP大模型论文:伯克利&DeepMind联合研究,RaLMSpec让检索增强LLM速度提升2-7倍!
关键字:解读,模型,步骤,语言,步长
文章来源:夕小瑶科技说
内容字数:10341字
内容摘要:
夕小瑶科技说 原创编辑 | Tscom引言:知识密集型NLP任务中的挑战与RaLM的潜力在知识密集型自然语言处理(NLP)任务中,传统的大语言模型面临着将海量知识编码进全参数化模型的巨大挑战。这不仅在训练和部署阶段需要大量的努力,而且在模型需要适应新数据或不同的下游任务时,问题更加严重。为了应对这些挑战,近期的研究提出了检索增强型语言模型(Retrieval-augmented Language Models, RaLM),它通过检索增强将参数化的语言模型与非参数化的知识库结合起来。
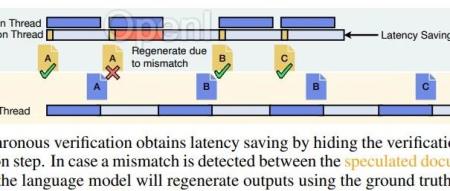
RaLM通过一次性(one-shot)或迭代(iterative)的检索与语言模型的交互,来辅助生成过程。尽管迭代式RaLM在生成质量上表现更好,但它由于频繁的检索步骤而遭受高昂的开销。因此,本文提出了一个问题:我们能否在不影响生成质量的情况下减少迭代式RaLM的开销?
为了解决这一问题,我们提出了RaLMSpec框架,它采用推测性检索(speculative retrieval)和批量验证(batched verification)来减少迭代式RaLM的服务开销,同时保证模型输出的正确性。RaLMSpe
原文链接:今日arXiv最热NLP大模型论文:伯克利&DeepMind联合研究,RaLMSpec让检索增强LLM速度提升2-7倍!
联系作者
文章来源:夕小瑶科技说
作者微信:xixiaoyaoQAQ
作者简介:更快的AI前沿,更深的行业洞见。聚集25万AI应用开发者、算法工程师和研究人员。一线作者均来自清北、国外顶级AI实验室和互联网大厂,兼备媒体sense与技术深度。
相关文章



全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。