AIGC动态欢迎阅读
内容摘要:
,智猩猩与智东西将于4月18-19日在北京共同举办2024中国生成式AI大会,阿里巴巴通义千问大模型技术负责人周畅,「清华系Sora」生数科技CEO唐家渝,云天励飞“云天天书”大模型技术负责人余晓填,Open-Sora开发团队潞晨科技创始人尤洋,鸿博股份副总裁、英博数科CEO周韡韡,优必选研究院执行院长焦继超,科大讯飞人形机器人首席科学家季超,腾讯研究科学家张驰等20+位嘉宾已确认带来演讲和报告,欢迎报名。导读本文转载自公众号:极市平台,原文来自知乎,作者为Kevin吴嘉文,本文讨论部署 LLaMa 系列模型常用的几种方案,并作速度测试。包括 Huggingface 自带的 LLM.int8(),AutoGPTQ,GPTQ-for-LLaMa,exllama,llama.cpp。
原文链接:https://zhuanlan.zhihu.com/p/641641929总结来看,对 7B 级别的 LLaMa 系列模型,经过 GPTQ 量化后,在 4090 上可以达到 140+ tokens/s 的推理速度。在 3070 上可以达到 40 tokens/s 的推理速度。
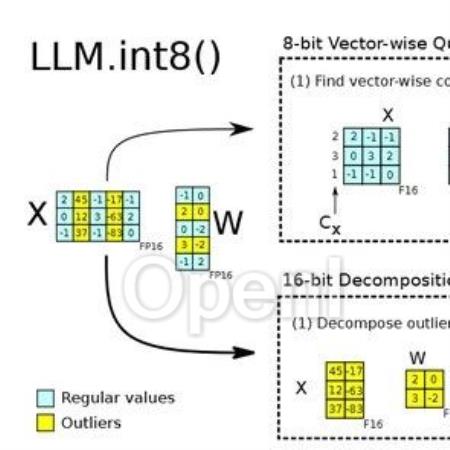
01LM.int8(
原文链接:LLaMa 量化部署常用方案总结
联系作者
文章来源:算法邦
作者微信:allplusai
作者简介:智猩猩矩阵账号之一,连接AI新青年,讲解研究成果,分享系统思考。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。