AIGC动态欢迎阅读
原标题:Transformer本可以深谋远虑,但就是不做
关键字:模型,语言,缓存,步骤,面包屑
文章来源:机器之心
内容字数:3851字
内容摘要:
机器之心报道
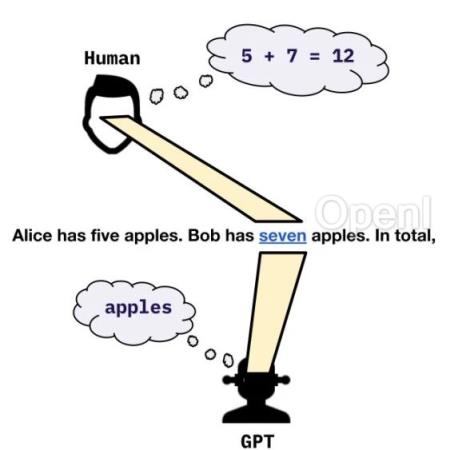
机器之心编辑部语言模型是否会规划未来 token?这篇论文给你答案。
「别让 Yann LeCun 看见了。」Yann LeCun 表示太迟了,他已经看到了。今天要介绍的这篇 「LeCun 非要看」的论文探讨的问题是:Transformer 是深谋远虑的语言模型吗?当它在某个位置执行推理时,它会预先考虑后面的位置吗?
这项研究得出的结论是:Transformer 有能力这样做,但在实践中不会这样做。
我们都知道,人类会思而后言。数十年的语言学研究表明:人类在使用语言时,内心会预测即将出现的语言输入、词或句子。
不同于人类,现在的语言模型在「说话」时会为每个 token 分配固定的计算量。那么我们不禁要问:语言模型会和人类一样预先性地思考吗?
近期的一些研究已经表明:可以通过探查语言模型的隐藏状态来预测下一 token 之后的更多 token。有趣的是,通过在模型隐藏状态上使用线性探针,可以在一定程度上预测模型在未来 token 上的输出,而干扰隐藏状态则可以对未来输出进行可预测的修改。
这些发现表明在给定时间步骤的模型激活至少在一定程度上可以预测未来输出。
但是,我们还不
联系作者
文章来源:机器之心
作者微信:almosthuman2014
作者简介:专业的人工智能媒体和产业服务平台
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。