AIGC动态欢迎阅读
原标题:8B文字多模态大模型指标逼近GPT4V,字节、华师、华科联合提出TextSquare
关键字:模型,数据,文本,字节跳动,性能
文章来源:机器之心
内容字数:8514字
内容摘要:
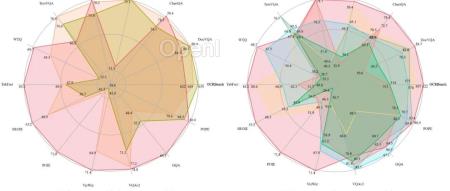
AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com。近期,多模态大模型 (MLLM) 在文本中心的 VQA 领域取得了显著进展,尤其是多个闭源模型,例如:GPT4V 和 Gemini,甚至在某些方面展现了超越人类能力的表现。但是开源模型的性能还远远落后于闭源模型,最近许多开创性的研究,例如:MonKey、LLaVAR、TG-Doc、ShareGPT4V 等已开始关注指令微调数据不足的问题。尽管这些努力取得了显著的效果,但仍存在一些问题,图像描述数据和 VQA 数据属于不同的领域,图像内容呈现的粒度和范围存在不一致性。此外,合成数据的规模相对较小,使得 MLLM 无法充分发挥潜力。论文标题:TextSquare: Scaling up Text-Centric Visual Instruction Tuning
原文链接:8B文字多模态大模型指标逼近GPT4V,字节、华师、华科联合提出TextSquare
联系作者
文章来源:机器之心
作者微信:almosthuman2014
作者简介:专业的人工智能媒体和产业服务平台
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。