AIGC动态欢迎阅读
原标题:Mixtral-8x7B MoE大模型微调实践,超越Llama2-65B
关键字:模型,李白,专家,参数,数据
文章来源:算法邦
内容字数:6642字
内容摘要:
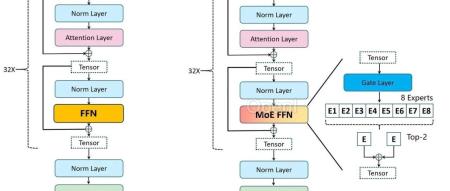
直播预告 | 5月14日晚7点,「智猩猩AI新青年讲座」第235讲正式开讲,慕尼黑工业大学视觉实验室陈振宇博士将直播讲解《三维室内场景纹理图生成》欢迎扫名~01前言Mixtral-8x7B在各大榜单中取得了及其优异的表现,本文主要分享我们微调Mixtral-8x7B MoE模型的初步实践。我们使用Firefly项目对其进行微调,在一张V100上,仅使用4.8万条数据对Mixtral-8x7B-v0.1基座模型微调了3000步,取得了非常惊艳的效果。
我们的模型在?Open LLM Leaderboard上的分数为70.34分,比Mixtral-8x7B-v0.1提升1.92分,比官方的chat模型低2.28分。若对训练数据和流程进行更精细的调整,应该还有较大的提升空间。注意,Mixtral-8x7B-v0.1为预训练模型,具有非常弱的指令遵从能力,我们在此基础上进行微调,旨在验证方法的有效性。若读者希望在自己的下游任务中进行微调,可基于Mixtral-8x7B-Instruct-v0.1进行微调。
我们也对比了其他主流的开源模型在?Open LLM Leaderboard的表现
原文链接:Mixtral-8x7B MoE大模型微调实践,超越Llama2-65B
联系作者
文章来源:算法邦
作者微信:allplusai
作者简介:智猩猩矩阵账号之一,聚焦生成式AI,重点关注模型与应用。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。