AIGC动态欢迎阅读
原标题:今日arXiv最热大模型论文:LoRA又有新用途,学得少忘得也少,成持续学习关键!
关键字:参数,任务,模型,数学,矩阵
文章来源:夕小瑶科技说
内容字数:5721字
内容摘要:
夕小瑶科技说 原创作者 | Axe_越自大模型(LLM)诞生以来,苦于其高成本高消耗的训练模式,学界和业界也在努力探索更为高效的参数微调方法。其中Low-Rank Adaptation(LoRA)自其诞生以来,就因其较低的资源消耗而受到广泛关注和使用。
LoRA通过学习低秩扰动(low-rank perturbations),从而在使用大模型适配下游任务时,只需要训练少量的参数即可达到一个很好的效果。尽管LoRA在资源效率上有明显优势,但其在处理复杂领域任务时的性能表现如何,尚未有定论。本文旨在填补这一空缺,以编程和数学两个具有挑战性的领域任务为例,探讨LoRA与全参数微调的性能。
论文标题:LoRA Learns Less and Forgets Less
论文链接:https://arxiv.org/pdf/2405.09673
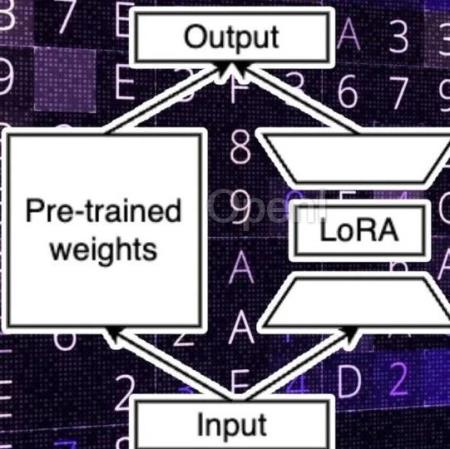
LoRA方法概述LoRA的思想非常简单,对于神经网络中的某些线性层(比如 Transformer 架构中的多头自注意力的权重矩阵 Q,K,V 或者前馈神经网络层的 W),不是直接对这些大参数矩阵的所有元素进行更新,而是引入较小的矩阵 A 和 B,并使得这些
原文链接:今日arXiv最热大模型论文:LoRA又有新用途,学得少忘得也少,成持续学习关键!
联系作者
文章来源:夕小瑶科技说
作者微信:xixiaoyaoQAQ
作者简介:专业、有趣、深度价值导向的科技媒体。聚集30万AI工程师、研究员,覆盖500多家海内外机构投资人,互联网大厂中高管和AI公司创始人。一线作者来自清北、国内外顶级AI实验室和大厂,兼备敏锐的行业嗅觉和洞察深度。商务合作:zym5189
相关文章



全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。